
1. 2025年的對話式語音 AI
大型語言模型(LLMs)是優秀的對話夥伴。
如果你曾經花時間與 ChatGPT 或 Claude 進行自由形式的對話,你會直覺地感受到與 LLM 交談感覺相當自然且廣泛實用。
LLMs 也擅長將非結構化資訊轉換為結構化資料。[1]
新型語音 AI 代理利用這兩種 LLM 能力 — 對話,以及從非結構化資料中提取結構 — 創造出一種全新的使用者體驗。
[1] 這裡我們是廣義地表達,而非指某些 LLM 的「結構化輸出」功能的狹義含義。
語音 AI 目前已在各種商業環境中被部署。例如:
- 在醫療預約前收集病患資料,
- 跟進潛在銷售線索,
- 處理越來越多樣化的客服中心任務,
- 協調公司間的排程和物流,以及
- 為幾乎所有類型的小型企業接聽電話。
在消費者方面,對話式語音(和視訊)AI 也開始進入社交應用和遊戲領域。開發者每天都在 GitHub 和社群媒體上分享個人語音 AI 專案和實驗。
2. 關於本指南
本指南是語音 AI 最新技術的快照。[2]
建立生產級語音代理相當複雜。許多元素從零開始實作並非易事。如果你開發語音 AI 應用,你可能會依賴框架來處理本文件中討論的許多事項。但我們認為了解這些組件如何配合是有用的,無論你是從頭開始建構所有內容,還是不是。
本指南直接受到 Sean DuBois 的開源書籍 WebRTC For the Curious 的啟發。自四年前首次發布以來,該書已幫助無數開發者快速掌握 WebRTC。[3]
本文件中的語音 AI 程式碼範例使用 Pipecat 開源框架。Pipecat 是一個供應商中立的即時 AI 代理層。[4] 我們在本文件中使用 Pipecat 是因為:
- 我們每天都用它來開發並協助維護它,所以我們對它很熟悉!
- Pipecat 目前是使用最廣泛的語音 AI 框架,NVIDIA、Google、AWS、OpenAI 和數百家新創公司的團隊都在利用並貢獻程式碼。
我們在本文件中嘗試提供一般性建議,而非推薦商業產品和服務。當我們強調特定供應商時,是因為它們被大比例的語音 AI 開發者使用。
讓我們開始吧……
[2] 我們最初為 2025 年 2 月的 AI 工程峰會撰寫本指南。我們在 2025 年 5 月中旬更新了它。
[3] webrtcforthecurious.com — WebRTC 與語音 AI 相關,我們將在後面的 WebSockets 和 WebRTC 部分討論。
[4] Pipecat 整合了超過 60 個 AI 模型和服務,並具有最先進的對話輪替偵測和中斷處理實作。你可以使用 Pipecat 編寫使用 WebSockets、WebRTC、HTTP 和電話系統與使用者通訊的程式碼。Pipecat 包含適用於各種基礎設施平台的傳輸實作,包括 Twilio、Telnyx、LiveKit、Daily 等。有適用於 JavaScript、React、iOS、Android 和 C++ 的 客戶端 Pipecat SDK。
3. 基本對話式 AI 循環
語音 AI 代理的基本「工作」是聆聽人類所說的內容,以某種有用的方式回應,然後重複這個序列。
現今生產環境中的語音代理幾乎都有非常相似的架構。語音代理程式在雲端運行並協調語音對語音循環。代理程式使用多個 AI 模型,有些在代理本地運行,有些通過 API 訪問。代理程式還使用 LLM 函數呼叫或結構化輸出與後端系統整合。
- 語音由使用者裝置上的麥克風捕獲,編碼後通過網路發送到雲端運行的語音代理程式。
- 輸入語音被轉錄,為 LLM 創建文字輸入。
- 文字被組合成上下文 — 提示 — 並由 LLM 執行推論。推論輸出通常會被代理程式邏輯過濾或轉換。[5]
- 輸出文字被發送到文字轉語音模型以創建音訊輸出。
- 音訊輸出被發送回使用者。
你會注意到語音代理程式在雲端運行,且文字轉語音、LLM 和語音轉文字處理都在雲端進行。長期來看,我們預期會看到更多 AI 工作負載在裝置上運行。然而,目前生產環境的語音 AI 非常以雲端為中心,原因有二:
- 語音 AI 代理需要使用最佳的 AI 模型,以可靠地執行複雜工作流程並保持低延遲。終端使用者裝置尚未擁有足夠的 AI 計算能力,無法以可接受的延遲運行最佳的 STT、LLM 和 TTS 模型。
- 目前大多數商業語音 AI 代理是通過電話與使用者通訊。對於電話通話,沒有終端使用者裝置 — 至少,沒有一個你可以在上面運行任何程式碼的裝置!
讓我們深入[6]這個代理協調世界,並回答以下問題:
- 哪些 LLM 最適合語音 AI 代理?
- 如何在長時間運行的會話中管理對話上下文?
- 如何將語音代理連接到現有的後端系統?[7]
- 如何知道你的語音代理表現良好?

[5] 例如,檢測常見的 LLM 錯誤和安全問題。
[6] 讓我們深入探討 — 編輯
[7] 例如,CRM、專有知識庫和客服中心系統。
4. 核心技術與最佳實踐
4.1. 延遲
建立語音代理在大多數方面與其他類型的 AI 工程相似。如果你有建立基於文字的多輪 AI 代理的經驗,你在該領域的許多經驗也將在語音方面派上用場。
最大的差異在於延遲。
人類在正常對話中期望快速回應。500毫秒的回應時間是典型的。長時間的停頓感覺不自然。
如果你正在建立語音 AI 代理,值得學習如何從終端使用者的角度準確測量延遲。
你經常會看到 AI 平台引用的延遲並非真正的「語音到語音」測量。這通常不是惡意的。從提供者的角度來看,測量延遲的簡單方法是測量推論時間。所以這就是提供者習慣思考延遲的方式。然而,這種伺服器端的視角並未考慮音訊處理、短語結束點延遲、網路傳輸和作業系統開銷。
手動測量語音到語音延遲很容易。
只需錄製對話,將錄音載入音訊編輯器,查看音訊波形,並測量從使用者語音結束到 LLM 語音開始的時間。
如果你為生產環境建立對話式語音應用程式,偶爾以這種方式檢查你的延遲數據是值得的。如果在進行這些測試時添加模擬網路封包丟失和抖動,那就更好了!
以程式方式測量真正的語音到語音延遲是具有挑戰性的。一些延遲發生在作業系統深處。因此,大多數可觀察性工具只測量到第一個(音訊)位元組的時間。這是總語音到語音延遲的合理代理,但請再次注意,你沒有測量的事項 — 如短語結束點變化和網路往返時間 — 如果你沒有方法追蹤它們,可能會成為問題。
如果你正在建立對話式 AI 應用程式,800毫秒的語音到語音延遲是一個很好的目標。以下是從使用者麥克風到雲端再返回的語音到語音往返的細分。這些數字相當典型,總計約為1秒。在當今的 LLM 中,持續達到800毫秒是具有挑戰性的,但並非不可能!
| 階段 | 時間 (毫秒) |
|---|---|
| macOS 麥克風輸入 | 40 |
| opus 編碼 | 21 |
| 網路堆疊和傳輸 | 10 |
| 封包處理 | 2 |
| 抖動緩衝區 | 40 |
| opus 解碼 | 1 |
| 轉錄和結束點檢測 | 300 |
| LLM 首字節時間 | 350 |
| 句子聚合 | 20 |
| TTS 首字節時間 | 120 |
| opus 編碼 | 21 |
| 封包處理 | 2 |
| 網路堆疊和傳輸 | 10 |
| 抖動緩衝區 | 40 |
| opus 解碼 | 1 |
| macOS 喇叭輸出 | 15 |
| 總毫秒數 | 993 |
語音到語音對話往返 — 延遲細分。
我們已經展示了 Pipecat 代理可以通過在同一個 GPU 啟用的叢集中託管所有模型,並優化所有模型以降低延遲而非提高吞吐量,從而實現 500 毫秒的語音到語音延遲。這種方法目前並不廣泛使用。託管模型成本高昂。而且開放權重 LLM 在語音 AI 中的使用頻率低於最佳專有模型,如 GPT-4o 或 Gemini。有關語音代理 LLM 的討論,請參閱下一節。
由於延遲對語音用例非常重要,因此在本指南中將經常提到延遲。

4.2. 語音用例的 LLMs
2023年3月GPT-4的發布開啟了當前語音AI的新時代。GPT-4是第一個既能維持靈活的多輪對話,又能被精確提示以執行有用工作的LLM。如今,GPT-4的繼任者 – GPT-4o – 仍然是對話式語音AI的主導模型。
現在有幾個模型在語音AI關鍵領域的表現已經與原始GPT-4一樣好或更好:
- 足夠低的延遲以進行互動式語音對話。
- 良好的指令遵循能力。[8]
- 可靠的函數呼叫。[9]
- 較低的幻覺率和其他不適當回應。
- 個性和語調。
- 成本。
[8] 提示模型執行特定任務有多容易?
[9] 語音AI代理heavily依賴函數呼叫。
但今天的GPT-4o也比原始GPT-4更好!特別是在指令遵循、函數呼叫和降低幻覺率方面。
GPT-4o的主要競爭對手是Google的Gemini 2.0 Flash。Gemini 2.0 Flash速度快,在指令遵循和函數呼叫方面與GPT-4o不相上下,且價格極具競爭力。
語音AI用例的要求相當高,通常使用最佳可用模型是合理的。在某個時間點,這種情況會改變,非最先進的模型也將足以在語音AI用例中廣泛採用。但目前還不是這樣。
4.2.1 LLM 延遲
Claude Sonnet本應是語音AI的絕佳選擇,但推理延遲(首個token的時間)並非Anthropic的優先事項。Claude Sonnet的中位數延遲通常是GPT-4o和Gemini Flash的兩倍,且P95分布範圍更大。
| 模型 | 中位數 TTFT (毫秒) | P95 TTFT (毫秒) |
|---|---|---|
| GPT-4o | 460 | 580 |
| GPT-4o mini | 290 | 420 |
| GPT-4.1 | 450 | 670 |
| Gemini 2.0 Flash | 380 | 450 |
| Llama 4 Maverick (Groq) | 290 | 360 |
| Claude Sonnet 3.7 | 1,410 | 2,140 |
OpenAI、Anthropic和Google API的首個token時間(TTFT)指標 - 2025年5月
一個粗略的經驗法則:LLM首個token時間在500毫秒或更低對大多數語音AI用例來說已經足夠好。GPT-4o的TTFT通常在400-500毫秒。Gemini Flash也類似。
4.2.2 成本比較
推理成本一直在定期且迅速下降。因此,一般來說,LLM成本在選擇使用哪個LLM時是最不重要的因素。Gemini 2.0 Flash最新公布的定價比GPT-4o便宜10倍。我們將看到這對語音AI領域有何影響。
| 模型 | 3分鐘對話 | 10分鐘對話 | 30分鐘對話 |
|---|---|---|---|
| GPT-4o | $0.009 | $0.08 | $0.75 |
| Gemini 2.0 Flash | $0.0004 | $0.004 | $0.03 |
多輪對話的會話成本隨著時間增長呈超線性增長。30分鐘的會話成本大約是3分鐘會話的100倍。您可以通過快取、上下文摘要和其他技術來降低長會話的成本。
請注意,成本隨著會話長度的增加呈超線性增長。除非您在會話期間修剪或摘要上下文,否則長會話的成本會成為問題。這對於語音到語音模型尤其如此(見下文)。
上下文增長的數學特性使得確定語音對話的每分鐘成本變得棘手。此外,API提供商越來越多地提供token快取功能,這可以抵消成本(並減少延遲),但增加了估算不同用例成本的複雜性。
OpenAI的OpenAI Realtime API自動token快取特別好用。Google最近為所有2.5版本模型推出了類似功能,稱為隱式快取。
4.2.3 開源 / 開放權重模型
Meta的Llama 3.3和4.0開放權重模型在基準測試中表現優於原始的GPT-4。目前,它們在商業用例中通常不如GPT-4o和Gemini。然而,能夠基於這些模型進行開發並在自己的基礎設施上運行它們具有重要意義。[11]
許多提供商提供Llama推理端點,而無伺服器GPU平台為部署自己的Llama提供了多種選擇。Meta最近宣布了新的第一方推理API,並強烈表示開放權重的Llama模型是公司的關鍵戰略重點。
Llama家族中一個有趣且功能強大的模型是Ultravox。Ultravox是一個開源的原生音訊LLM。Ultravox背後的公司還提供企業級的託管語音到語音API。Ultravox利用多種技術將Llama 3.3擴展到音訊領域,並改進基礎模型在語音AI用例中的指令遵循和函數調用性能。Ultravox是開源AI生態系統優勢以及原生音訊模型引人注目潛力的典範。
我們在2025年看到開源/開放權重模型取得了很大進展。Llama 4剛剛推出,社群仍在評估其在多輪對話AI用例中的實際表現。來自阿里巴巴的新Qwen 3模型是優秀的中型模型,在早期基準測試中與Llama 4平分秋色。此外,DeepSeek、Google (Gemma)和Microsoft (Phi)未來的開放權重模型很可能成為語音AI用例的良好選擇。
[11] 如果您計劃為您的用例微調LLM,Llama 3.3 70B是一個很好的起點。下文將詳細介紹微調。
4.2.4 語音到語音模型呢?
語音到語音模型是一個令人興奮的相對較新的發展。語音到語音LLM可以接受音訊而非文字作為輸入,並能直接產生音訊輸出。這消除了語音代理協調循環中的語音轉文字和文字轉語音部分。
語音到語音模型的潛在優勢是:
- 更低的延遲。
- 更好地理解人類對話的細微差別。
- 更自然的語音輸出。
OpenAI和Google都發布了語音到語音API。大多數訓練大型模型和構建語音AI應用的人都認為語音到語音模型是語音AI的未來。
然而,目前的語音到語音模型和API還不足以應對大多數生產環境中的語音AI用例。
當今最好的語音到語音模型確實比當今最好的文字到語音模型聽起來更自然。OpenAI的gpt4o-audio-preview [12]模型確實聽起來像是語音AI未來的預覽。
[12] OpenAI音訊API文檔
不過,語音到語音模型還沒有文字模式LLM那麼成熟和可靠。
- 理論上可以實現更低的延遲,但音訊使用的token比文字多。較大的token上下文處理起來對LLM來說更慢。在實際應用中,目前音訊模型在長時間多輪對話中通常比文字模型慢。[13]
- 更好的理解似乎確實是這些模型的真正優勢。這在Gemini 2.0 Flash音訊輸入中特別明顯。對於gpt-4o-audio-preview,情況目前不太明確,它是一個比文字模式GPT-4o更小且功能稍弱的模型。
- 更自然的語音輸出目前確實可以明顯感知到。但音訊LLM在音訊模式下確實有一些奇怪的輸出模式,這些在文字模式下不太常見:詞語重複、有時落入恐怖谷的話語標記,以及偶爾無法完成句子。
[13] 音訊模型的這種延遲問題顯然可以通過快取、巧妙的API設計以及模型本身的架構演進來解決。
這些問題中最大的是多輪音訊所需的更大上下文大小。解決這個問題並獲得原生音訊優勢而不受上下文大小缺點影響的一種方法是將每個對話輪次處理為文字和音訊的混合。使用音訊處理最近的用戶訊息;使用文字處理其餘的對話歷史。
OpenAI的測試版語音到語音產品 — OpenAI Realtime API — 速度快且語音質量驚人。但該API背後的模型是較小的gpt-4o-audio-preview,而非完整的GPT-4o。因此,指令遵循和函數調用不如完整版好。使用Realtime API管理對話上下文也很棘手,且API有一些新產品的粗糙邊緣。[14]
Google Multimodal Live API是另一個有前途的 — 且處於演進早期的 — 語音到語音服務。這個API提供了Gemini模型近期未來的展望:長上下文窗口、出色的視覺能力、快速推理、強大的音訊理解、代碼執行和搜索基礎。與OpenAI Realtime API一樣,Multimodal Live API尚未成為大多數生產語音AI應用的正確選擇。
請注意,語音到語音API相對昂貴。我們為OpenAI Realtime API構建了一個計算器,顯示成本如何隨會話長度擴展,同時考慮了OpenAI非常好的自動token快取功能。
我們預計2025年語音到語音領域將取得大量進展。但生產環境中的語音AI應用從多模型方法轉向使用語音到語音API的速度仍是一個開放性問題。
[14] 參見關於Realtime API的詳細說明
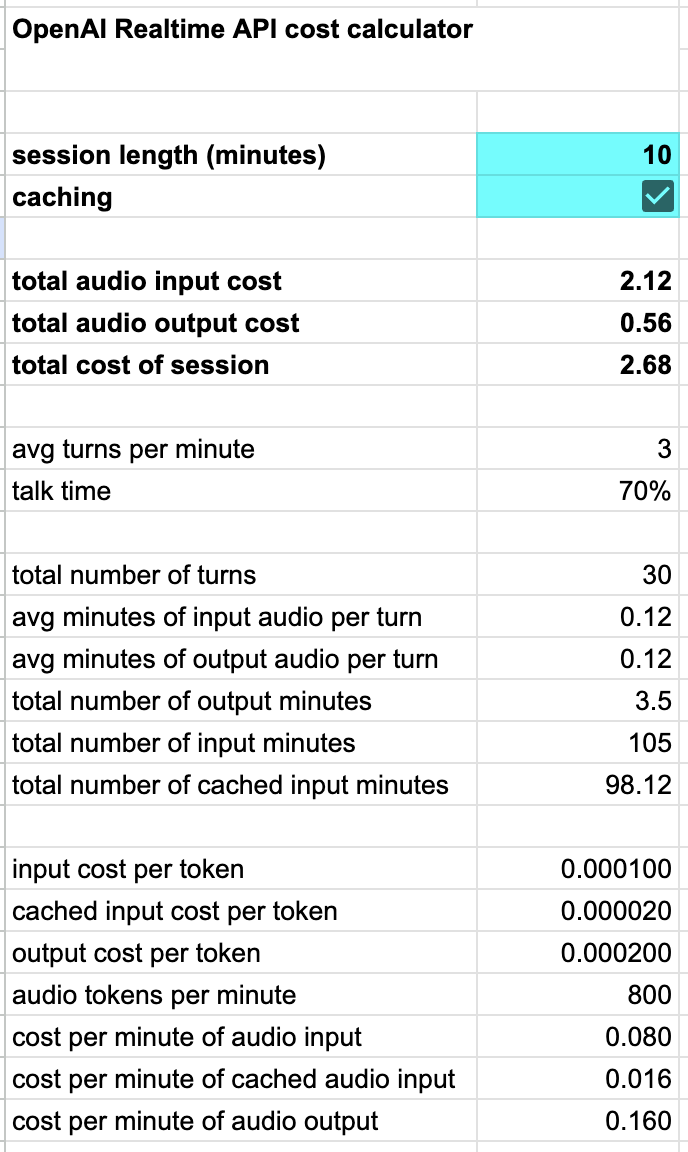
OpenAI Realtime API成本計算器
4.3. 語音轉文字
語音轉文字是語音AI的「輸入」階段。語音轉文字也常被稱為轉錄或ASR(自動語音識別)。
對於語音AI用例,我們需要非常低的轉錄延遲和非常低的詞錯誤率。可惜的是,優化語音模型以降低延遲會對準確性產生負面影響。
目前有幾個非常好的轉錄模型,但它們不是為低延遲而設計的。Whisper是一個在許多產品和服務中使用的開源模型。它非常好,但通常首個token的生成時間在500毫秒或更長,因此很少用於對話式語音AI用例。
4.3.1 Deepgram和Gladia
目前大多數生產環境中的語音AI代理使用Deepgram或Gladia進行語音轉文字。Deepgram是一家商業語音轉文字AI實驗室和API平台,長期以來一直提供低延遲、低詞錯誤率和低成本的絕佳組合。Gladia是該領域的較新參與者(成立於2022年),在多語言支持方面具有特殊優勢。
Deepgram的模型可作為自助服務API使用,也可作為Docker容器供客戶在自己的系統上運行。大多數人開始時通過API使用Deepgram語音轉文字。對於美國用戶,首個token的生成時間通常為150毫秒。
管理可擴展的GPU集群是一項重要的持續性運維工作,因此從API轉向在自己的基礎設施上託管模型不應該沒有充分理由就進行。充分的理由包括:
- 保持音訊/轉錄數據的私密性。Deepgram提供BAA和數據處理協議,但一些客戶可能希望完全控制音訊和轉錄數據。美國以外的客戶可能有法律義務將數據保留在自己的國家或地區內。(請注意,根據默認的Deepgram服務條款,他們可以使用您通過API發送給他們的所有數據進行訓練。企業計劃可以選擇退出此項。)
- 減少延遲。Deepgram在美國以外沒有推理服務器。從歐洲使用Deepgram,首個token生成時間約為250毫秒;從印度使用則約為350毫秒。
Deepgram提供微調服務,如果您的用例包含相對不常見的詞彙、語音風格或口音,這可以幫助降低詞錯誤率。
Gladia是我們在英語世界以外的新語音AI項目中最常見的語音轉文字提供商。Gladia總部位於法國,在美國和歐洲都有推理服務器,並支持100多種語言。
Gladia提供託管API和在自己的基礎設施上運行其模型的選項。Gladia的API可用於需要歐洲數據駐留的應用程序。
4.3.2 提示可以幫助LLM
很大比例的轉錄錯誤源於實時流中轉錄模型可用的上下文非常有限。
當今的LLM足夠聰明,可以解決轉錄錯誤。當LLM執行推理時,它可以訪問完整的對話上下文。因此,您可以告訴LLM輸入是用戶語音的轉錄,它應該相應地進行推理。
You are a helpful, concise, and reliable voice assistant. Your primary goal is to understand the user's spoken requests, even if the speech-to-text transcription contains errors. Your responses will be converted to speech using a text-to-speech system. Therefore, your output must be plain, unformatted text.
When you receive a transcribed user request:
1. Silently correct for likely transcription errors. Focus on the intended meaning, not the literal text. If a word sounds like another word in the given context, infer and correct. For example, if the transcription says "buy milk two tomorrow" interpret this as "buy milk tomorrow".
2. Provide short, direct answers unless the user explicitly asks for a more detailed response. For example, if the user says "what time is it?" you should respond with "It is 2:38 AM". If the user asks "Tell me a joke", you should provide a short joke.
3. Always prioritize clarity and accuracy. Respond in plain text, without any formatting, bullet points, or extra conversational filler.
4. If you are asked a question that is time dependent, use the current date, which is February 3, 2025, to provide the most up to date information.
5. If you do not understand the user request, respond with "I'm sorry, I didn't understand that."
Your output will be directly converted to speech, so your response should be natural-sounding and appropriate for a spoken conversation.
語音AI代理的示例提示語言。
4.3.3 其他語音轉文字選項
我們預計2025年語音轉文字領域將出現許多新發展。截至2025年4月初,我們正在追蹤的一些新發展:
- OpenAI 剛剛發布了兩個新的語音轉文字模型,gpt-4o-transcribe和gpt-4o-mini-transcribe。
- 另外兩家備受推崇的語音技術公司,Speechmatics和AssemblyAI,已開始更多關注對話式語音用例,推出流式API和具有更快首個token生成時間的模型。
- NVIDIA正在發布開源語音模型,在基準測試中表現極為出色。
- 推理公司Groq託管的Whisper Large v3 Turbo版本現在的中位數首個token生成時間低於300毫秒,使其成為對話式語音應用的可選項。這是我們看到的第一個達到這種延遲的Whisper API服務。
所有大型雲服務都有語音轉文字API。目前,對於低延遲語音AI用例,它們都不如Deepgram或Gladia好。
但在以下情況下,您可能想使用Azure AI Speech、Amazon Transcribe或Google Speech-to-Text:
- 您已經與這些雲提供商之一有大量承諾支出或數據處理安排。
- 您有很多這些雲提供商的創業積分可以使用!
4.3.4 使用Google Gemini進行轉錄
利用Gemini 2.0 Flash作為低成本、原生音訊模型優勢的一種方法是同時使用Gemini 2.0進行對話生成和轉錄。
為此,我們需要運行兩個並行的推理過程。
- 一個推理過程生成對話回應。
- 另一個推理過程轉錄用戶的語音。
- 每個音訊輸入僅用於一個輪次。完整的對話上下文始終是最近用戶語音的音訊,加上所有先前輸入和輸出的文字轉錄。
- 這給您提供了兩全其美的優勢:對當前用戶話語的原生音訊理解;整個上下文的token數量減少。[15]
[15] 用文字替換音訊可將token數量減少約10倍。對於十分鐘的對話,這將處理的總token數量 - 因此輸入token的成本 - 減少約100倍。(因為對話歷史在每個輪次都會累積。)
以下是將這些並行推理過程實現為Pipecat管道的代碼。
pipeline = Pipeline(
[
transport.input(),
audio_collector,
context_aggregator.user(),
ParallelPipeline(
[ # transcribe
input_transcription_context_filter,
input_transcription_llm,
transcription_frames_emitter,
],
[ # conversation inference
conversation_llm,
],
),
tts,
transport.output(),
context_aggregator.assistant(),
context_text_audio_fixup,
]
)
邏輯如下。
- 對話LLM接收文字形式的對話歷史,加上每個新輪次的用戶語音作為原生音訊,並輸出對話回應。
- 輸入轉錄LLM接收相同的輸入,但輸出最近用戶語音的字面轉錄。
- 在每個對話輪次結束時,用戶音訊上下文條目被替換為該音訊的轉錄。
Gemini的每token成本如此之低,以至於這種方法實際上比使用Deepgram進行轉錄更便宜。
重要的是要理解,我們在這裡不是將Gemini 2.0 Flash用作完整的語音到語音模型,但我們確實在使用其原生音訊理解能力。我們提示模型使其以兩種不同的「模式」運行,對話和轉錄。
以這種方式使用LLM展示了SOTA LLM架構和功能的強大。這種方法新到仍處於實驗階段,但早期測試表明,它可以產生比任何其他當前技術更好的對話理解和更準確的轉錄。然而,也有缺點。轉錄延遲不如使用專門的語音轉文字模型好。運行兩個推理過程和交換上下文元素的複雜性很大。通用LLM容易受到提示注入和上下文遵循錯誤的影響,而專門的轉錄模型不會受到這些影響。
以下是轉錄的系統指令(提示)。
You are an audio transcriber. You are receiving audio from a user. Your job is to transcribe the input audio to text exactly as it was said by the user.
You will receive the full conversation history before the audio input, to help with context. Use the full history only to help improve the accuracy of your transcription.
Rules:
- Respond with an exact transcription of the audio input.
- Do not include any text other than the transcription.
- Do not explain or add to your response.
- Transcribe the audio input simply and precisely.
- If the audio is not clear, emit the special string "".
- No response other than exact transcription, or "", is allowed.
4.4. 文字轉語音
文字轉語音是語音到語音處理循環的輸出階段。
語音AI開發者根據以下因素選擇語音模型/服務:
- 語音聽起來有多自然(整體質量)[16]
- 延遲[17]
- 成本
- 語言支持
- 詞級時間戳支持
- 自定義語音、口音和發音的能力
[16] 發音、語調、節奏、重音、韻律、情感表達。
[17] 首個音訊位元組的輸出時間。
2024年語音選項顯著擴展。新創公司紛紛出現。最佳語音品質大幅提升。且每個供應商都改善了延遲問題。
與語音轉文字一樣,所有大型雲端供應商都有文字轉語音產品。[18] 但大多數語音AI開發者並不使用它們,因為目前新創公司的模型表現更好。
[18] Azure AI Speech、Amazon Polly和Google Cloud Text-to-Speech。
在即時對話語音模型領域中最具影響力的實驗室有(按字母順序):
- Cartesia – 使用創新的狀態空間模型架構,同時實現高品質和低延遲。
- Deepgram – 優先考慮延遲和低成本。
- ElevenLabs – 強調情感和上下文真實感。
- Rime – 提供可自定義的TTS模型,專門針對對話語音訓練。
這四家公司都擁有強大的模型、工程團隊以及穩定高效的API。Cartesia、Deepgram和Rime的模型可以部署在您自己的基礎設施上。
| 每分鐘成本(約) | 中位數TTFB (毫秒) | P95 TTFB (毫秒) | 平均前置靜音時間 (毫秒) | |
|---|---|---|---|---|
| Cartesia | $0.02 | 190 | 260 | 160 |
| Deepgram | $0.008 | 150 | 320 | 260 |
| ElevenLabs Turbo v2 | $0.08 | 300 | 510 | 160 |
| ElevenLabs Flash v2 | $0.04 | 170 | 190 | 100 |
| Rime | $0.024 | 340 | 980 | 160 |
大規模使用時的每分鐘約略成本及首位元組時間指標 – 2025年2月。請注意,成本取決於承諾使用量和所用功能。平均前置靜音毫秒是指在第一個語音幀之前,音訊流中的平均初始靜音間隔。
與語音轉文字一樣,非英語語音模型的品質和支援差異很大。如果您正在為非英語使用場景構建語音AI,您可能需要進行更廣泛的測試 — 測試更多服務和更多語音,以找到令您滿意的解決方案。
所有語音模型有時會發音錯誤,且不一定知道如何發音專有名詞或不常見的詞彙。
某些服務提供調整發音的功能。如果您預先知道文字輸出將包含特定專有名詞,這會很有幫助。如果您的語音服務不支援語音調整,您可以提示LLM輸出特定單詞的「聽起來像」的拼寫。例如,用in-vidia代替NVIDIA。
Replace "NVIDIA" with "in vidia" and replace
"GPU" with "gee pee you" in your responses.
通過LLM文字輸出調整發音的提示語言示例
對於對話語音使用場景,能夠追蹤用戶聽到的文字對於維持準確的對話上下文很重要。這要求模型除了音訊外還能生成詞級時間戳元數據,並且時間戳數據可以重建回原始輸入文字。這是語音模型的相對較新功能。上表中除了ElevenLabs Flash外的所有模型都支援詞級時間戳。
{
"type": "timestamps",
"context_id": "test-01",
"status_code": 206,
"done": false,
"word_timestamps": {
"words": ["What's", "the", "capital", "of", "France?"],
"start": [0.02, 0.3, 0.48, 0.6, 0.8],
"end": [0.3, 0.36, 0.6, 0.8, 1]
}
}
來自Cartesia API的詞級時間戳。
此外,一個真正穩固的即時串流API非常有幫助。對話語音應用程式經常並行觸發多個音訊推理。語音代理程式碼需要能夠中斷進行中的推理,並將每個推理請求與輸出流關聯起來。來自語音模型提供商的串流API都相對較新且仍在發展中。目前,Cartesia和Rime在Pipecat中擁有最成熟的串流支援。
我們預計語音模型在2025年將繼續進步。
4.5. 音訊處理
一個好的語音AI平台或函式庫大多會隱藏音訊捕獲和處理的複雜性。但如果您構建複雜的語音代理,在某些時候您會遇到音訊處理中的錯誤和邊緣情況。[19] 因此,值得快速瀏覽一下音訊輸入管道。
[19] …這適用於軟體中的所有事物,也許也適用於生活中的大多數事物。
4.5.1 麥克風和自動增益控制
現今的麥克風是極其複雜的硬體設備,與大量低階軟體相結合。這通常很好 — 我們可以從內置於移動設備、筆記型電腦和藍牙耳機中的微型麥克風獲得出色的音訊。
但有時這些低階軟體不會按我們的期望運作。特別是藍牙設備可能會為語音輸入增加數百毫秒的延遲。作為語音AI開發者,這在很大程度上超出了您的控制範圍。但值得注意的是,延遲可能會因特定用戶使用的操作系統和輸入設備而有很大差異。

大多數音訊捕獲管道會對輸入信號應用一定程度的自動增益控制。這通常是您想要的,因為它可以補償諸如用戶與麥克風的距離等因素。您通常可以禁用部分自動增益控制,但在消費級設備上,您通常無法完全禁用它。
4.5.2 回音消除
如果用戶將手機貼在耳邊,或戴著耳機,您不需要擔心本地麥克風和揚聲器之間的反饋。但如果用戶使用免提電話,或使用沒有耳機的筆記型電腦,那麼良好的回音消除就極為重要。
回音消除對延遲非常敏感,因此回音消除必須在設備上運行(而不是在雲端)。如今,出色的回音消除功能已內置於電話系統、網頁瀏覽器和WebRTC原生移動SDK中。[20]
因此,如果您使用語音AI、WebRTC或電話SDK,您應該有可以在幾乎所有實際場景中「正常運作」的回音消除功能。如果您自行開發語音AI捕獲管道,您將需要弄清楚如何整合回音消除邏輯。例如,如果您正在構建基於WebSocket的React Native應用程式,默認情況下您將沒有任何回音消除功能。[21]
[20] 請注意,Firefox的回音消除效果不是很好。我們建議語音AI開發者以Chrome和Safari作為主要平台進行構建,並且只在時間允許的情況下將Firefox作為次要平台進行測試。
[21] 我們最近幫助某人調試他們的React Native應用程式的音訊問題。根本原因是他們沒有意識到需要實現回音消除,因為他們沒有使用語音AI或WebRTC SDK。
4.5.3 噪音抑制、語音和音樂
用於電話和WebRTC的音訊捕獲管道幾乎總是默認為「語音模式」。語音可以比音樂壓縮得多,而且噪音減少和回音消除算法對於較窄頻帶信號更容易實現。
許多電話平台僅支援8khz音訊。按現代標準來看,這種品質明顯較低。如果您通過具有此限制的系統路由,您對此無能為力。您的用戶可能會也可能不會注意到品質差異 — 大多數人對電話通話音訊的期望較低。
WebRTC支援非常高品質的音訊。[22] WebRTC的默認設置通常是48khz採樣率、單聲道、32 kbs Opus編碼,以及中等噪音抑制算法。這些設置針對語音進行了優化。它們適用於各種設備和環境,通常是語音AI的正確選擇。
音樂在這些設置下聽起來不會好!
如果您需要通過WebRTC連接傳送音樂,您需要:
- 關閉回音消除(用戶需要戴耳機)。
- 關閉噪音抑制。
- 可選擇啟用立體聲。
- 增加Opus編碼比特率(單聲道64 kbs是個不錯的目標,立體聲則為96 kbs或128 kbs)。
[22] 高品質音訊的一些使用場景:
- 與LLM教師的音樂課。
- 錄製包含背景聲音或音樂的播客。
- 互動式生成AI音樂。
4.5.4 編碼
編碼是指音訊數據如何格式化以通過網絡連接傳送的通用術語。[23]
[23] (或用於保存在文件中。)
實時通信常用的編碼包括:
- 16位PCM格式的未壓縮音訊。
- Opus — WebRTC和某些電話系統。
- G.711 — 一種廣泛支援的標準電話編解碼器。
| 編解碼器 | 比特率 | 品質 | 使用場景 |
|---|---|---|---|
| 16-bit PCM | 384 kbps (單聲道 24 kHz) | 非常高(接近無損) | 語音錄製、嵌入式系統、簡單解碼至關重要的環境 |
| Opus 32 kbps | 32 kbps | 良好(針對語音優化的心理聲學壓縮) | 視訊通話、低頻寬串流、播客 |
| Opus 96 kbps | 96 kbps | 非常好到優秀(心理聲學壓縮) | 串流、音樂、音訊存檔 |
| G.711 (8 kHz) | 64 kbps | 差(有限頻寬,以語音為中心) | 傳統VoIP系統、電話、傳真傳輸、語音訊息 |
語音AI最常用的音訊編解碼器
Opus是這三個選項中最好的。Opus內置於網頁瀏覽器中,從頭開始設計為低延遲編解碼器,且非常高效。它在各種比特率下表現良好,並支援語音和高保真使用場景。
16位PCM是「原始音訊」。您可以直接將PCM音訊幀發送到軟體聲道(假設正確指定了採樣率和數據類型)。但請注意,這種未壓縮的音訊通常不是您想通過互聯網連接發送的內容。24khz PCM的比特率為384 kbs。這是一個足夠大的比特率,以至於許多來自終端用戶設備的實際連接將難以實時傳送這些位元組。
4.5.5 伺服器端噪音處理和說話者隔離
語音轉文字和語音活動檢測模型通常可以忽略一般環境噪音 – 街道聲音、狗吠聲、靠近麥克風的嘈雜風扇、鍵盤點擊聲。因此,對於許多人與人之間的使用場景至關重要的傳統「噪音抑制」算法對於語音AI並不那麼重要。
但有一種音訊處理對語音AI特別有價值:主要說話者隔離。主要說話者隔離可抑制背景語音。這可以顯著提高轉錄準確性。
想像一下嘗試在機場等環境中與語音代理交談。您的手機麥克風可能會捕捉到大量來自登機口廣播和路過人群的背景語音。您不希望LLM看到的文字轉錄中包含那些背景語音!
或者想像一下在客廳中有電視或收音機在背景中播放的用戶。由於人類通常相當擅長過濾低音量的背景語音,人們不一定會想到在撥打客戶支援電話前關閉電視或收音機。
您可以在自己的語音AI管道中使用的最佳可用說話者隔離模型由Krisp提供。許可證針對企業用戶,價格不便宜。但對於大規模商業用途,語音代理性能的提升足以證明成本的合理性。
OpenAI最近在其Realtime API中推出了新的噪音減少功能。參考文檔在這裡。
pipeline = Pipeline(
[
transport.input(),
krisp_filter,
vad_turn_detector,
stt,
context_aggregator.user(),
llm,
tts,
transport.output(),
context_aggregator.assistant(),
]
)
包含Krisp處理元素的Pipecat管道
4.5.6 語音活動檢測
語音活動檢測階段是幾乎每個語音AI管道的一部分。VAD將音訊片段分類為「語音」和「非語音」。我們將在下方的輪次檢測部分詳細討論VAD。
4.6. 網路傳輸
4.6.1 WebSockets和WebRTC
WebSockets和WebRTC都被AI服務用於音訊串流。
WebSockets非常適合伺服器對伺服器的使用場景。對於延遲不是主要考慮因素的場景,它們也很好用,並且非常適合原型設計和一般開發。
WebSockets不應該在生產環境中用於客戶端-伺服器的即時媒體連接。
如果您正在開發瀏覽器或原生行動應用程式,且對話延遲對您的應用程式很重要,您應該使用WebRTC連接來從您的應用程式發送和接收音訊。
WebSockets用於終端用戶設備的即時媒體傳輸的主要問題是:
- WebSockets建立在TCP上,因此音訊串流會受到隊頭阻塞的影響。
- WebRTC使用的Opus音訊編解碼器與WebRTC的頻寬估計和封包節奏(擁塞控制)邏輯緊密耦合,使WebRTC音訊串流能夠應對各種現實世界的網路行為,這些行為可能會導致WebSocket連接累積延遲。
- Opus音訊編解碼器具有非常好的前向錯誤修正功能,使音訊串流能夠應對相對較高的封包丟失。(但這只有在您的網路傳輸能夠丟棄延遲到達的封包且不進行隊頭阻塞時才有幫助。)
- WebRTC音訊會自動加上時間戳,因此播放和中斷邏輯變得非常簡單。
- WebRTC包含詳細的性能和媒體質量統計的鉤子。一個好的WebRTC平台將為您提供詳細的儀表板和分析。這種級別的可觀察性對於WebSockets來說介於非常困難和不可能之間。
- WebSocket重新連接邏輯很難穩健地實現。您將不得不建立一個ping/ack框架(或完全測試並理解您的WebSocket庫提供的框架)。TCP超時和連接事件在不同平台上的行為不同。
- 最後,現今好的WebRTC實現都配備了非常好的回音消除、噪音減少和自動增益控制。
您可以通過兩種方式使用WebRTC。
- 通過雲端中的WebRTC伺服器路由。
- 在客戶端設備和語音AI處理程序之間建立直接連接。
對於許多現實世界的使用場景,通過雲端伺服器路由將表現得更好(參見下方的網路路由)。雲端基礎設施還使得直接連接不能輕易或可擴展地支援的許多功能成為可能(多參與者會話、與電話系統集成、錄音)。
但「無伺服器」WebRTC適合許多語音AI使用場景。Pipecat通過SmallWebRTCTransport類支援無伺服器WebRTC。而像Hugging Face的FastRTC這樣的框架完全圍繞這種網路模式構建。

4.6.2 HTTP
HTTP對於語音AI仍然有用且重要!HTTP是互聯網上服務互連的通用語言。REST API是HTTP。Webhooks是HTTP。
文字導向的推理通過HTTP進行,因此語音AI管道通常會調用HTTP API來處理對話循環的LLM部分。
語音代理在與外部服務和內部API集成時也使用HTTP。一個有用的技術是將LLM函數調用代理到HTTP端點。這將語音AI代理程式碼和開發運維與函數實現解耦。
多模態AI應用程式通常會想要實現HTTP和WebRTC代碼路徑。想像一個支援文字模式和語音模式的聊天應用程式。對話狀態需要通過任一連接路徑訪問,這對客戶端和伺服器端代碼都有影響(例如,Kubernetes pods和Docker容器的架構方式)。
HTTP的兩個缺點是延遲和實現長期雙向連接的困難。
- 建立加密的HTTP連接需要多次網路往返。即使對於高度優化的伺服器,實現低於30ms的媒體連接設置時間也相當困難,而現實中的首位元組發送時間即使對於高度優化的伺服器也接近100ms。
- 長期雙向HTTP連接的管理難度足夠大,以至於您通常最好直接使用WebSockets。
- HTTP是基於TCP的協議,因此影響WebSockets的相同隊頭阻塞問題也是HTTP的問題。
- 通過HTTP發送原始二進制數據不夠常見,以至於大多數API選擇對二進制數據進行base64編碼,這增加了媒體串流的比特率。
這就引出了QUIC…

一個同時使用HTTP和WebRTC進行網路通信的語音AI代理。
4.6.3 QUIC和MoQ
QUIC是一種新的網路協議,設計用作最新版HTTP(HTTP/3)的傳輸層 — 並且靈活地支援其他互聯網規模的使用場景。
QUIC是一種基於UDP的協議,解決了上述所有HTTP問題。使用QUIC,您可以獲得更快的連接時間、雙向串流,以及沒有隊頭阻塞。Google和Facebook一直在穩步推出QUIC,因此現在,您的一些HTTP請求是以UDP而非TCP封包穿越互聯網的。[24]
[24] 如果您已經在互聯網上構建東西很長時間了,這有點令人震驚。HTTP一直是基於TCP的協議!
QUIC將成為互聯網媒體串流未來的重要部分。但遷移到基於QUIC的即時媒體串流協議需要時間。構建基於QUIC的語音代理的一個障礙是Safari尚未支援基於QUIC的WebSockets演進版本WebTransport。
媒體超過QUIC IETF工作組[25]旨在開發一個「簡單的低延遲媒體傳輸解決方案,用於媒體的攝取和分發」。與所有標準一樣,用最簡單的構建塊支援最廣泛的重要使用場景並不容易。人們對使用QUIC進行點播視頻串流、大規模視頻廣播、實時視頻串流、具有大量參與者的低延遲會話以及低延遲1:1會話感到興奮。
[25] IETF媒體超過QUIC工作組
即時語音AI使用場景正在以恰到好處的時機增長,可以影響MoQ標準的發展。
4.6.4 網路路由
長距離網路連接對延遲和即時媒體可靠性都是有問題的,無論底層網路協議是什麼。
對於即時媒體傳輸,您希望您的伺服器盡可能靠近您的用戶。
例如,從英國的用戶到AWS us-west-1(北加州)託管的伺服器的封包往返時間通常約為140毫秒。相比之下,同一用戶到AWS eu-west-2的RTT通常為15毫秒或更少。

從英國的用戶到AWS us-west-1的RTT比到AWS eu-west-2多約100ms
這是超過100毫秒的差異 — 如果您的語音到語音延遲目標是1,000毫秒,這是您延遲「預算」的百分之十。
邊緣路由
您可能無法在靠近所有用戶的地方部署伺服器。
要在世界各地的用戶實現15ms的RTT,需要部署至少40個全球數據中心。這是一個大型的開發運維工作。而且如果您運行需要GPU的工作負載,或依賴於自身沒有全球部署的服務,這可能是不可能的。
您無法欺騙光速。[26] 但您可以嘗試避免路由變化和擁塞。
[26] 古老的網路工程師智慧 – 編者註
關鍵是保持您的公共互聯網路由盡可能短。將您的用戶連接到靠近他們的邊緣伺服器。從那裡,使用私有路由。
這種邊緣路由減少了中位數封包RTT。通過私有骨幹網的英國→北加州路由可能約為100毫秒。100毫秒(長距離私有路由)+ 15毫秒(通過公共互聯網的第一跳)= 115毫秒。這個私有路由中位數RTT比公共路由中位數RTT快25毫秒。

從英國到AWS us-west-1的邊緣路由。通過公共網路的第一跳仍有15ms的RTT。但通過私有網路到北加州的長路由有100ms的RTT。總RTT為115ms,比從英國到us-west-1的公共路由快25ms。它也顯著更穩定(更少的封包丟失和更低的抖動)。
比中位數RTT改善更關鍵的是改善的傳輸可靠性和更低的抖動。[27] 私有路由的P95 RTT將顯著低於公共路由的P95。[28]
這意味著通過長距離公共路由的即時媒體連接將明顯比使用私有路由的連接更有延遲。回想一下,我們試圖盡可能快地傳輸每個音訊封包,但我們必須按順序播放音訊封包。單個延遲的封包迫使我們擴大抖動緩衝區,保留其他已接收的封包直到延遲的封包到達。(或者,直到我們決定它花費了太長時間,我們用花哨的數學或有故障的音訊樣本填補空白。)
[27] 抖動是封包穿越路由所需時間的變化性。
[28] P95是指標的第95百分位測量值。P50是中位數測量值(第50百分位)。粗略地說,我們將P50視為平均情況,P95則捕捉「典型最壞情況」連接的大致感覺。

抖動緩衝區 — 較大的抖動緩衝區直接轉化為音訊和視頻中較大的感知延遲。保持抖動緩衝區盡可能小對良好的用戶體驗有顯著貢獻。
一個好的WebRTC基礎設施提供商將提供邊緣路由。他們將能夠向您展示他們的伺服器集群位置,並提供顯示其私有路由性能的指標。
4.7. 輪次檢測
輪次檢測意味著確定用戶何時完成說話並期望LLM回應。
在學術文獻中,這個問題的各個方面被稱為短語檢測、語音分段和終點檢測。(有學術文獻關於這一點是一個線索,表明這不是一個簡單的問題。)
我們(人類)每次與他人交談時都會進行輪次檢測。而我們並不總是做對![29]
因此輪次檢測是一個困難的問題,沒有完美的解決方案。但讓我們談談常用的各種方法。
[29] 特別是在音訊通話中,當我們沒有視覺提示幫助我們時。
4.7.1 語音活動檢測
目前,語音AI代理進行輪次檢測最常見的方式是假設長時間的停頓意味著用戶已經完成說話。
語音AI代理管道使用一個小型專門的語音活動檢測模型來識別停頓。VAD模型已經被訓練來將音訊片段分類為語音或非語音。(這比僅基於音量水平來識別停頓要穩健得多。)
您可以在語音AI連接的客戶端或伺服器端運行VAD。如果您需要在客戶端進行大量音訊處理,您可能需要在客戶端運行VAD來促進這一點。例如,也許您正在嵌入式設備上識別喚醒詞,只有在短語開頭檢測到喚醒詞時才通過網路發送音訊。嘿,Siri…
不過,通常在語音AI代理處理循環中運行VAD會更簡單一些。而且如果您的用戶是通過電話連接的,您沒有可以運行VAD的客戶端,所以您必須在伺服器上進行。
語音AI最常用的VAD模型是Silero VAD。這個開源模型在CPU上高效運行,支援多種語言,適用於8khz和16khz音訊,並且作為wasm包可用於網頁瀏覽器。在即時單聲道音訊串流上運行Silero通常只需要典型虛擬機CPU核心的1/8。
輪次檢測算法將有幾個配置參數:
- 輪次結束所需的停頓長度。
- 觸發開始說話事件所需的語音片段長度。
- 將每個音訊片段分類為語音的置信度水平。
- 語音片段的最小音量。

語音活動檢測處理步驟,此處配置為在語音轉文字之前運行
# Pipecat's names and default values
# for the four configurable VAD
# parameters
VAD_STOP_SECS = 0.8
VAD_START_SECS = 0.2
VAD_CONFIDENCE = 0.7
VAD_MIN_VOLUME = 0.6
調整這些參數可以大大改善特定使用場景的輪次檢測行為。
4.7.2 按鍵通話
基於語音停頓進行輪次檢測的明顯問題是,有時人們停頓但並未完成說話。
個人說話風格各不相同。人們在某些類型的對話中比其他類型的對話中停頓更多。
設置較長的停頓間隔會創造生硬的對話 — 非常糟糕的用戶體驗。但使用較短的停頓間隔,語音代理會頻繁地打斷用戶 — 同樣是糟糕的用戶體驗。
最常見的替代停頓基礎輪次檢測的方法是按鍵通話。按鍵通話意味著要求用戶在開始說話時按下或按住按鈕,並在完成說話時再次按下按鈕或釋放它。(想想老式對講機的工作方式。)
使用按鍵通話,輪次檢測是明確的。但用戶體驗與純粹交談不同。
電話語音AI代理無法使用按鍵通話。
4.7.3 終點標記
您也可以使用特定詞語作為輪次結束標記。(想想卡車司機在CB無線電上說「完畢」。)
識別特定終點標記的最簡單方法是對每個轉錄片段運行正則表達式匹配。但您也可以使用小型語言模型來檢測終點詞或短語。
使用明確終點標記的語音AI應用相當罕見。用戶必須學習如何與這些應用交談。但這種方法對於專門的使用場景可以非常有效。
例如,去年我們看到了一個不錯的演示,是某人作為副項目為自己建立的寫作助手。他們使用各種命令短語來指示輪次終點和切換模式。
4.7.4 上下文感知輪次檢測(語義VAD和智能輪次)
當人類進行輪次檢測時,他們使用各種提示:
- 識別像「嗯」這樣的填充詞,這些詞可能表示繼續說話。
- 語法結構。
- 對模式的了解,例如電話號碼有特定數量的字母。
- 語調和發音模式,如在停頓前拉長最後一個詞。
深度學習模型非常擅長識別模式。LLM具有大量潛在的語法知識,可以被提示進行短語終點檢測。較小的專門分類模型可以在語言、語調和發音模式上進行訓練。
隨著語音代理在商業上變得越來越重要,我們預計會看到用於上下文感知語音AI輪次檢測的新模型。
有兩種主要方法:
- 訓練一個可以實時運行的小型輪次檢測模型。將此模型與VAD模型結合使用或替代VAD模型。輪次檢測模型可以被訓練來對文字進行模式匹配。文字模式輪次檢測模型在轉錄後的處理管道中內聯運行,通常需要在特定轉錄模型的輸出上進行訓練才能有效。或者,輪次檢測模型可以被訓練為直接在音訊上操作,這允許輪次檢測分類同時考慮語言級別模式和語調、語速和發音模式。原生音訊輪次檢測模型不需要任何轉錄信息,因此可以與轉錄並行運行,這可以提高性能。
- 使用大型LLM和少量示例提示來執行輪次檢測。大型LLM通常太慢,無法內聯使用,阻塞管道。為了解決這個問題,您可以分割管道,並行進行輪次檢測和「貪婪」對話推理。
[30] Pipecat開源智能輪次檢測模型
4.8. 中斷處理
中斷處理意味著允許用戶打斷語音AI代理。中斷是對話的正常部分,因此優雅地處理中斷很重要。
要實現中斷處理,您需要讓管道中的每個部分都可以被取消。您還需要能夠在客戶端上非常快速地停止音訊播放。
通常,您正在使用的框架會在觸發中斷時負責停止所有處理。但如果您直接使用的API以快於實時的速度向您發送原始音訊幀,您將不得不手動停止播放並清空音訊緩衝區。
4.8.1 避免虛假中斷
有幾個值得注意的非預期中斷來源。
- 被歸類為語音的瞬態噪音。好的VAD模型在將語音與「噪音」分離方面做得非常出色。但某些類型的短促、尖銳的初始音訊在出現在話語開頭時會附帶中等程度的語音置信度。咳嗽和鍵盤點擊都屬於這一類。您可以調整VAD起始段長度和置信度水平,以嘗試最小化這種中斷來源。權衡是延長起始段長度和提高置信度閾值會為您確實想要檢測為完整話語的非常短的短語創造問題。[31]
- 回聲消除失敗。回聲消除算法並不完美。從靜音到語音播放的轉換特別具有挑戰性。如果您做了大量的語音代理測試,您可能聽到過您的機器人在開始說話時打斷了自己。罪魁禍首是回聲消除允許少量初始語音音訊反饋到您的麥克風。最小VAD起始段長度有助於避免這個問題。應用指數平滑[32]到音訊音量水平以避免急劇的音量轉換也有幫助。
- 背景語音。VAD模型不會區分用戶語音和背景語音。如果背景語音比您的音量閾值更大,背景語音將觸發中斷。說話者隔離音訊處理步驟可以減少由背景語音引起的虛假中斷。請參閱上面伺服器端噪音處理和說話者隔離部分的討論。
4.8.2 在中斷後維持準確的上下文
因為LLM生成輸出的速度比實時快,當發生中斷時,您通常會有排隊等待發送給用戶的LLM輸出。
通常,您希望對話上下文與用戶實際聽到的內容匹配(而不是您的管道以快於實時的速度生成的內容)。
您可能也在以文本形式保存對話上下文。[33]
所以您需要一種方法來確定用戶實際聽到了什麼!
最好的語音轉文本服務可以報告詞級時間戳數據。使用這些詞級時間戳來緩衝和組裝與用戶聽到的音訊匹配的助手消息文本。請參閱上面文本轉語音部分關於詞級時間戳的討論。Pipecat會自動處理這個問題。
[31] Pipecat的標準管道配置結合了VAD和轉錄事件,以嘗試避免虛假中斷和錯過的話語。
[33] 標準上下文結構是由OpenAI開發的用戶/助手消息列表格式。
4.9. 管理對話上下文
LLM是無狀態的。這意味著對於多輪對話,您需要在每次生成新回應時將所有先前的用戶和代理消息——以及其他配置元素——重新輸入到LLM中。
Turn 1:
User: What's the capital of France?
LLM: The capital of France is Paris.
Turn 2:
User: What's the capital of France?
LLM: The capital of France is Paris.
User: Is the Eiffel Tower there?
LLM: Yes, the Eiffel Tower is in Paris.
Turn 3:
User: What's the capital of France?
LLM: The capital of France is Paris.
User: Is the Eiffel Tower there?
LLM: Yes, the Eiffel Tower is in Paris.
User: How tall is it?
LLM: The Eiffel Tower is about 330 meters tall.
每輪向LLM發送整個對話歷史。
對於每個推理操作——每個對話輪次——您可以向LLM發送:
- 系統指令
- 對話消息
- LLM可以使用的工具(函數)
- 配置參數(例如,溫度)
4.9.1 LLM API之間的差異
這種一般設計對於今天所有主要的LLM都是相同的。
但各種提供商的API之間存在差異。OpenAI、Google和Anthropic都有不同的消息格式,工具/函數定義結構的差異,以及系統指令指定方式的差異。
有第三方API網關和軟件庫可以將API調用轉換為OpenAI的格式。這很有價值,因為能夠在不同的LLM之間切換很有用。但這些服務並不總是能夠正確地抽象差異。新功能和每個API獨有的功能並不總是受支持。(有時在轉換層中也有錯誤。)
在AI工程的這些相對早期階段,是否抽象仍然是一個問題。[34]
例如,Pipecat將上下文消息和工具定義轉換為OpenAI格式並從中轉換。但是否以及如何做到這一點是社區相當大的辯論主題![35]
[34] 備註:請Claude想出一個好的哈姆雷特笑話 – 編輯
[35] 如果您對這類話題感興趣,請考慮加入Pipecat Discord並參與那裡的對話。
4.9.2 在輪次之間修改上下文
必須管理多輪上下文增加了開發語音AI代理的複雜性。另一方面,可以追溯性地修改上下文可能很有用。對於每個對話輪次,您可以決定確切要發送給LLM的內容。
LLM並不總是需要完整的對話上下文。縮短或總結上下文可以減少延遲,降低成本,並提高語音AI代理的可靠性。關於這個主題的更多內容在下面的腳本和指令遵循部分。
4.10. 函數調用
生產級語音AI代理嚴重依賴LLM函數調用。
函數調用用於:
- 獲取信息用於檢索增強生成(RAG)。
- 與現有後端系統和API交互。
- 與電話技術堆棧集成——呼叫轉移、排隊、發送DTMF音調。
- 腳本遵循——實現工作流狀態轉換的函數調用。
4.10.1 語音AI上下文中的函數調用可靠性
隨著語音AI代理被部署於越來越複雜的用例,可靠的函數調用變得越來越重要。
最先進的LLM在函數調用方面正在穩步改進,但語音AI用例往往將LLM函數調用能力推向極限。
語音AI代理傾向於:
- 在多輪對話中使用函數。在多輪對話中,隨著每輪添加用戶和助手消息,提示會變得越來越複雜。這種提示複雜性降低了LLM函數調用能力。
- 定義多個函數。通常需要五個或更多函數用於語音AI工作流。
- 在一個會話中多次調用函數。
我們對所有主要AI模型發布進行了大量測試,並經常與訓練這些模型的人交談。很明顯,上述所有屬性相對於用於訓練當前一代LLM的數據來說都有些偏離分佈。
這意味著即使當前一代LLM在一般函數調用基準上表現良好,它們也會在語音AI用例中遇到困難。不同的LLM和同一模型的不同更新在函數調用方面的表現各不相同,在不同情況下對不同類型的函數調用的表現也各不相同。
如果您正在構建語音AI代理,開發自己的評估來測試應用程序的函數調用性能很重要。請參閱下面的語音AI評估部分。
4.10.2 函數調用延遲
函數調用會增加延遲——可能是很大的延遲——有四個原因:
- 當LLM決定需要函數調用時,它會輸出函數調用請求消息。然後您的代碼為特定請求的函數執行操作,然後再次使用相同的上下文加上函數調用結果消息進行推理。所以每次調用函數時,您必須進行兩次推理調用而不是一次。
- 函數調用請求不能被流式傳輸。我們需要整個函數調用請求消息才能執行函數調用。
- 向提示添加函數定義可能會增加延遲。這有點模糊;開發專門針對延遲的評估來測量向提示添加函數定義的額外延遲會很好。但很明顯,至少有些API在某些時候,無論是否實際調用函數,在啟用工具使用時都有更高的中位數TTFT。
- 您的函數可能很慢!如果您正在與遺留後端系統交互,您的函數可能需要很長時間才能返回。
每次用戶說完話,您都需要提供相當快的音訊反饋。如果您知道您的函數調用可能需要很長時間才能返回,您可能想要輸出語音告訴用戶發生了什麼並請他們等待。

包含函數調用的推理的TTFT。LLM TTFT為450毫秒,吞吐量為每秒100個標記。如果函數調用請求塊為100個標記,則輸出函數調用請求需要1秒。然後我們執行函數並再次運行推理。這次,我們可以流式傳輸輸出,所以450毫秒後我們有了可以使用的第一個標記。完整推理的TTFT為1,450毫秒(不包括執行函數本身所需的時間)。
您可以:
- 在執行函數調用之前始終輸出消息。「請稍等,我正在為您執行X...」
- 設置看門狗計時器,只有在函數調用循環在計時器觸發前未完成時才輸出消息。「仍在處理中,請再等一會兒...」
當然,也可以兩者都用。而且您可以在執行長時間運行的函數調用時播放背景音樂。[36]
[36] 不過請不要用Jeopardy主題曲。
4.10.3 處理中斷
LLM被訓練為期望函數調用請求消息和函數調用響應消息作為匹配的對。
這意味著:
- 您需要停止您的語音到語音推理循環,直到所有函數調用完成。請參閱下面關於異步函數調用的說明。
- 如果函數調用被中斷且永遠不會完成,您需要在上下文中放入一個函數調用響應消息,表明...某些內容。
這裡的規則是,如果LLM調用函數,您需要在上下文中放入一對請求/響應消息。
- 如果您在上下文中放入一個懸而未決的函數調用請求消息,然後繼續多輪對話,您正在創建一個與LLM訓練方式不同的上下文。(有些API不允許這樣做。)
- 如果您根本不在上下文中放入請求/響應對,您就是在教LLM(通過上下文學習)不要調用該函數。[37]同樣,結果是不可預測的,可能不是您想要的。
[37] 參見論文,語言模型是少樣本學習者。
Pipecat通過在每次啟動函數調用時將請求/響應消息對插入上下文來幫助您遵循這些上下文管理規則。(當然,您可以覆蓋此行為並直接管理函數調用上下文消息。)
以下是這種模式的樣子,用於以兩種不同方式配置的函數調用:運行至完成和可中斷。
User: Please look up the price of 1000 widgets.
LLM: Please wait while I look up the price for 1000 widgets.
function call request: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
function call response: { status: IN_PROGRESS }
初始上下文訊息。函數呼叫請求訊息和函數呼叫回應佔位符。
User: Please look up the price of 1000 widgets.
function call request: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
function call response: { result: { price: 12.35 } }
函數呼叫完成時的上下文。
User: Please look up the price of 1000 widgets.
LLM: Please wait while I look up the price for 1000 widgets.
function call request: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
function call response: { status: IN_PROGRESS }
User: Please lookup the price of 1000 pre-assembled modules.
LLM: Please wait while I also look up the price for 1000 pre-assembled modules.
function call request: { name: "price_lookup", args: { item: "pre_assembled_module", quantity: 1000 } }
function call response: { status: IN_PROGRESS }
佔位符允許對話在函數呼叫運行時繼續進行,而不會「混淆」LLM。
User: "Please look up the price of 1000 widgets."
LLM: "Please wait while I look up the price for 1000 widgets."
function call request: { name: "price_lookup", args: { item: "widget", quantity: 1000 } }
function call response: { status: CANCELLED }
User: Please lookup the price of 1000 pre-assembled modules.
LLM: Please wait while I look up the price for 1000 pre-assembled modules.
function call request: { name: "price_lookup", args: { item: "pre_assembled_module", quantity: 1000 } }
function call response: { status: IN_PROGRESS }
如果函數呼叫配置為可中斷,則如果使用者在函數呼叫進行中說話,它將被取消。
4.10.4 流式模式和函數呼叫區塊
在語音AI代理程式碼中,您幾乎總是在流式模式下執行對話推理呼叫。這使您能夠盡快獲得前幾個內容區塊,這對於語音到語音回應延遲很重要。
然而,流式模式和函數呼叫是一個尷尬的組合。流式傳輸對函數呼叫區塊沒有幫助。在組裝完LLM的完整函數呼叫請求訊息之前,您無法呼叫函數。[38]
[38] 如果您使用的是AI框架,該框架可能會對您隱藏這種複雜性。
以下是對推理提供商在繼續發展其API時的一些反饋:請提供一種模式,可以原子地傳遞函數呼叫區塊,並與任何流式內容區塊隔離。這將顯著降低使用LLM提供商API的程式碼的複雜性。
4.10.5 如何以及在哪裡執行函數呼叫
當LLM發出函數呼叫請求時,您該怎麼做?以下是一些常用的模式:
- 直接在您的程式碼中執行與請求函數同名的函數呼叫。這是您在幾乎所有LLM函數呼叫文件示例中看到的內容。
- 根據參數和上下文將請求映射到操作。將此視為要求LLM進行通用函數呼叫,您在程式碼中進行消歧。這種模式的優點是,如果您給LLM提供少量函數選擇,LLM通常在函數呼叫方面表現更好。[39]
- 將函數呼叫代理到客戶端。這種模式在應用程式(非電話)上下文中可用。例如,想像一個get_location()函數。您想要使用者設備的當前位置,因此您需要連接到該設備上的地理查詢API。
- 將函數呼叫代理到網路端點。這在企業環境中通常是一種特別有用的模式。定義一組與內部API互動的函數。然後在您的程式碼中創建一個抽象,將這些函數呼叫作為HTTP請求執行。
[39] 在這裡將函數呼叫視為一個寬泛的類別——形式上而非口語上的函數。您可以從查找表返回值。您可以運行SQL查詢。

函數呼叫模式
4.10.6 非同步函數呼叫
有時您不想立即從函數呼叫返回。您知道您的函數將需要不可預測的長時間才能完成。也許它根本不會完成。也許您甚至想啟動一個長時間運行的進程,可以隨時間在上下文中添加內容。
想像一個步行旅遊應用程式,讓使用者表達對他們在旅途中可能看到的事物的興趣。「如果我們經過任何著名作家居住過的地方,我特別想聽聽這些。」這種架構的一個很好的方式是讓LLM在使用者表達特定興趣時呼叫函數。該函數將啟動一個背景進程,在找到與興趣相關的任何內容時將資訊注入上下文。
目前使用LLM函數呼叫無法直接實現這點。函數呼叫的請求/回應訊息必須一起出現在上下文中。
所以與其定義一個這樣形狀的函數:
register_interest_generator(interest: string) -> Iterator[Message]
你需要做類似這樣的事情:
create_interest_task_and_return_success_immediately (interest: string, context_queue_callback: Callable[Message]) -> Literal["in_progress", "canceled", "success", "failure"]
關於這個主題的更多討論,請參閱下方的執行非同步推理任務部分。
隨著LLM和API不斷發展以更好地支援多模態對話使用場景,我們希望看到LLM研究人員探索圍繞非同步函數和作為生成器的長時間運行函數的想法。
4.10.7 平行和複合函數呼叫
平行函數呼叫意味著LLM可以在單一推理回應中請求多個函數呼叫。複合函數呼叫意味著LLM可以靈活地連續呼叫多個函數,將函數串聯在一起以執行複雜操作。
這些都是令人興奮的功能!
但它們也增加了語音代理行為的變異性。這意味著您需要開發評估和監控,以測試平行和複合函數呼叫在實際對話中是否按預期工作。
處理平行函數呼叫會使您的代理程式碼更加複雜。我們通常建議人們禁用平行函數呼叫,除非有特定用途。
當複合函數呼叫運作良好時,感覺就像魔法一樣。我們最喜歡的複合函數呼叫早期案例之一是看到Claude Sonnet 3.5將函數串聯在一起,根據檔案名稱和時間戳從檔案中載入資源。
User: Claude, load the most recent picture I have of the Eiffel Tower.
function call request: <list_files()>
function call response: <['eiffel_tower_1735838843.jpg', 'empire_state_building_1736374013.jpg', 'eiffel_tower_1737814100.jpg', 'eiffel_tower_1737609270.jpg',
'burj_khalifa_1737348929.jpg']
function call request: <load_resource('eiffel_tower_1737814100.jpg')>
function call response: <{ 'success': 'Image loaded successfully', 'image': … }>
LLM: I have loaded an image of the Eiffel Tower. The image shows the Eiffel
Tower on a cloudy day.
LLM找出如何將兩個函數 – list_files() 和 load_resource() – 串聯起來,以回應特定指令。這兩個函數在工具列表中有描述。但這種串聯行為並非透過提示來實現的。
複合函數呼叫是SOTA LLM的相對較新功能。性能是「參差不齊的」– 令人驚訝地好,但又令人沮喪地不一致。
4.11. 多模態性
LLM現在除了文字外,還可以處理和生成音訊、圖像和影片。
我們之前談到了語音到語音模型。這些是能夠接收音訊輸入並產生音訊輸出的模型。
SOTA模型的多模態能力正在迅速發展。
GPT-4o、Gemini Flash和Claude Sonnet都具有非常好的視覺能力 – 它們都接受圖像作為輸入。這些模型的視覺支援最初專注於描述圖像內容和轉錄圖像中出現的文字。每次發布都會擴展功能。計數物體、識別邊界框以及更好地理解圖像中物體之間關係的能力都是較新版本中可用的有用功能。
Gemini Flash可以對影片輸入進行推理,包括理解影片和音訊軌道。[40]
一類有趣的新型語音啟用應用程式是可以「看到」您的螢幕並幫助在本地機器或網頁瀏覽器上執行任務的助手。許多人已經建立了語音驅動網頁瀏覽的框架。
我們認識的幾位程式設計師現在說話的時間和打字一樣多。將語音輸入連接到Cursor或Windsurf相當容易。[41]也可以連接螢幕截圖,讓您的AI程式設計助手能夠確切看到您所看到的內容 – 編輯器中的程式碼、您正在構建的網頁應用程式的UI狀態、終端機中的Python堆疊追蹤。這種完全多模態的AI程式設計助手感覺像是我們在本文中談到的未來的另一個縮影。[42]
[40] 您可以通過從影片中提取個別幀並將這些幀作為圖像嵌入上下文中,使用GPT-4o和Claude處理影片。這種方法有局限性,但對某些「影片」用例效果良好。
[41] 兩個流行的新程式設計編輯器,具有深度AI整合和工具。
[42] 參見swyx在OpenAI Dev Day 2024新加坡的演講,「工程AI代理」。
目前,所有SOTA模型以不同組合支援多模態性。
- GPT-4o (gpt-4o-2024-08-06) 具有文字和圖像輸入,以及文字輸出。
- gpt-4o-audio-preview 具有文字和音訊輸入,以及文字和音訊輸出。(沒有圖像輸入。)
- Gemini Flash 具有文字、音訊、圖像和影片輸入,但只有文字輸出。
- OpenAI的新語音轉文字和文字轉語音模型完全可控且建立在gpt-4o基礎上,但專門用於文字和音訊之間的轉換:gpt-4o-transcribe、gpt-4o-mini-transcribe和gpt-4o-mini-tts。
多模態支援正在迅速發展,我們預計上述列表很快就會過時!
對於語音AI,多模態性最大的挑戰是音訊和圖像使用大量token,而更多token意味著更高的延遲。
| 範例媒體 | 大約token數量 |
|---|---|
| 一分鐘語音音訊轉為文字 | 150 |
| 一分鐘語音音訊保持為音訊 | 2,000 |
| 一張圖像 | 250 |
| 一分鐘影片 | 15,000 |
對於某些應用程式,一個重大的工程挑戰是在處理大量圖像的同時實現對話式延遲。對話式延遲要求保持上下文較小或依賴供應商特定的快取API。圖像會向上下文添加大量token。
想像一個在您的電腦上持續運行並觀察您螢幕作為其工作循環一部分的個人助理代理。您可能希望能夠問:「一小時前我正要閱讀一則推文時接到電話,然後我忘記了它並關閉了分頁。那則推文是什麼?」
一小時前相當於近百萬個token。即使您的模型可以在其上下文中容納百萬個token[43],每次對話都使用那麼多token的成本和延遲都是難以接受的。
[43] 你好,Gemini!
您可以將影片摘要為文字,並只在上下文中保留摘要。您可以計算嵌入並進行類似RAG的查詢。LLM在特徵摘要和使用函數呼叫觸發複雜RAG查詢方面表現相當出色。但這兩種方法的工程實現都很複雜。
最終,最大的槓桿是上下文快取。所有SOTA API提供商都提供某種形式的快取支援。目前的快取功能對於語音AI用例來說都還不完美。我們預計今年快取API會有所改進,因為多模態、多輪對話用例會得到訓練SOTA模型的人更多關注。
5. 使用多個AI模型
現今的生產級語音AI代理使用多個深度學習模型的組合。[44]
如我們所討論的,典型的語音AI處理循環使用語音轉文字模型轉錄用戶的語音,將轉錄的文字傳遞給LLM生成回應,然後執行文字轉語音步驟來生成代理的語音輸出。
此外,現今許多生產級語音代理以複雜多樣的方式使用多個模型。
[44] 即使是來自OpenAI和Google的測試版語音到語音API也使用專用的VAD和降噪模型來實現輪次檢測。
5.1. 使用多個微調模型
大多數語音AI代理使用來自OpenAI或Google(有時是Anthropic或Meta)的SOTA[45]模型。使用最新、表現最佳的模型很重要,因為語音AI工作流通常處於模型能力的鋸齒狀前沿[46]邊緣。語音代理需要能夠遵循複雜指令,以自然方式與人進行開放式對話,並可靠地使用函數和工具。
[45] SOTA — state of the art(最先進技術)— 是一個廣泛使用的AI工程術語,大致意味著「來自領先AI實驗室的最新大型模型」。
但對於某些專業用例,為對話的不同狀態微調模型是有意義的。微調模型可以比大型模型更小、更快、運行成本更低,同時在特定任務上表現同樣出色(甚至更好)。
想像一個協助從大型工業供應目錄訂購零件的代理。對於這項任務,您可能會訓練幾個不同的模型,每個模型專注於不同類別:塑膠材料、金屬材料、緊固件、管道、電氣、安全設備等。
[46] 沃頓商學院教授Ethan Mollick創造了「鋸齒狀前沿」一詞,用來描述SOTA模型能力的複雜邊緣區域 — 有時令人驚訝地好,有時令人沮喪地差。
微調模型通常可以「學習」兩個重要類別的內容:
- 嵌入知識 — 模型可以學習事實。
- 回應模式 — 模型可以學習以特定方式轉換數據,這也包括學習對話模式和流程。
我們假設的工業供應公司擁有大量原始數據:
- 一個非常大的知識庫,包含數據表、製造商建議、價格以及有關目錄中每個零件的內部數據。
- 文字聊天記錄、電子郵件鏈和與人工支援代理的轉錄電話對話。

為特定對話主題使用微調模型。可以採用多種架構方法。在此例中,每個對話輪次開始時,路由器LLM會對完整上下文進行分類。
將這些原始數據轉化為微調模型的數據集是一項大工作,但可行。所需的數據清理、數據集創建、模型訓練和模型評估都是已經被充分理解的問題。
一個重要提示:不要直接跳到微調 — 從提示工程開始。
提示工程幾乎總能達到與微調相同的任務結果。微調的優勢在於能夠使用更小的模型,這可以轉化為更快的推理和更低的成本。[47]
使用提示工程,您可以更容易地開始並比微調更快地迭代。[48]
當初步探索如何為不同對話狀態使用不同模型時,可以將您的提示視為微型「模型」。您是通過製作一個大型、特定上下文的提示來教導LLM該做什麼。
- 對於嵌入知識,實現一個能夠從知識庫中提取信息並將搜索結果組合成有效提示的搜索功能。有關更多信息,請參見下方的RAG和記憶部分。
- 對於回應模式,嵌入您期望模型如何回應不同問題的示例。有時,只需幾個示例就足夠了。有時,您需要大量示例 — 100個或更多。
[47] 如果您有興趣深入了解提示工程與微調的比較,請參閱這兩篇經典論文:Language Models Are Few-shot Learners和A Comprehensive Survey of Few-shot Learning。
[48] 遵循經典工程建議:先讓它工作,再讓它快速,最後讓它便宜。在考慮從提示工程轉向微調之前,至少要先完成「讓它快速」這一階段的一半工作。(如果有必要的話。)
5.2. 執行非同步推理任務
有時您想使用LLM執行一項需要相對較長時間運行的任務。請記住,在我們的核心對話循環中,我們的目標是大約一秒(或更短)的回應時間。如果一項任務需要超過幾秒鐘,您有兩個選擇:
- 告訴用戶正在發生什麼並請他們等待。「請稍等,我正在為您查詢...」
- 非同步執行較長的任務,允許對話在後台任務進行的同時繼續。「我會為您查詢。在我查詢的同時,您有其他問題嗎?」
如果您正在非同步執行推理任務,您可能會選擇為該特定任務使用不同的LLM。(因為它與核心對話循環解耦。)您可能會使用一個比語音回應可接受的速度更慢的LLM,或者是您為特定任務微調過的LLM。
非同步推理任務的幾個例子:
- 實現內容「護欄」。(參見內容護欄部分。)
- 創建圖像。
- 生成在沙盒中運行的代碼。
推理模型[49]最近的驚人進展擴展了我們可以要求LLM做的事情。不過,您不能將這些模型用於語音AI對話循環,因為它們通常會花費大量時間產生思考token,然後才輸出可用的結果。不過,將推理模型作為多模型語音AI架構的非同步部分使用效果很好。
[49] 推理模型的例子包括DeepSeek R1、Gemini Flash 2.0 Thinking和OpenAI o3-mini。
非同步推理通常由LLM函數呼叫觸發。一個簡單的方法是定義兩個函數。
perform_async_inference()— 當LLM決定應該執行任何長時間運行的推理任務時,會呼叫此函數。您可以定義多個這樣的函數。請注意,您需要啟動非同步任務,然後立即返回基本的成功啟動任務回應,以確保函數呼叫請求和回應訊息在上下文中正確排序。[50]queue_async_context_insertion()— 當您的非同步推理完成時,由您的協調層呼叫此函數。這裡棘手的是,如何將結果插入上下文將取決於您嘗試做的事情,以及您使用的LLM/API允許什麼。一種方法是等待任何進行中的對話輪次結束(包括所有函數呼叫的完成),將非同步推理結果放入特別製作的用戶訊息中,然後執行另一個對話輪次。
[50] 請參閱非同步函數呼叫。
5.3. 內容護欄
語音AI代理有幾個弱點,這些弱點在某些使用場景中會造成重大問題。
- 提示注入(Prompt injection)
- 幻覺(Hallucination)
- 過時的知識
- 產生不適當或不安全的內容
內容護欄是指嘗試檢測上述任何問題的程式碼的通用術語 — 保護LLM免受意外和惡意提示注入的影響;在將不良的LLM輸出發送給用戶之前攔截它。
使用特定模型(或多個模型)作為護欄有幾個潛在優勢:
- 小型模型可能非常適合作為護欄和安全監控。識別有問題的內容可能是一項相對專業的任務。(事實上,特別是對於提示注入緩解,您不一定需要一個可以以完全通用方式被提示的模型。)
- 使用不同的模型進行護欄工作的優勢在於它不會與您的主要模型有完全相同的弱點。至少在理論上是這樣。
幾個開源代理框架都有護欄組件。
- llama-guard是Meta的llama-stack的一部分
- NeMO Guardrails是一個開源工具包,用於為基於LLM的對話應用添加可編程護欄

NVIDIA的NeMo Guardrails框架支持的五種護欄類型。圖表來自NeMo Guardrails文檔。
這兩個框架都是為文本聊天而設計的,而不是語音AI。但兩者都有有用的想法和抽象概念,如果您正在考慮護欄、安全性和內容審核,值得一看。
值得注意的是,與一年前相比,LLM在避免所有這些問題方面已經有了極大的進步。
一般來說,幻覺在大型實驗室的最新模型中已不再是主要問題。現在,我們只經常看到兩類幻覺。
- LLM「假裝」呼叫函數,但實際上並沒有這樣做。這可以通過提示來修復。您需要良好的評估來確保您的提示不會出現這種情況。當您在評估中看到函數呼叫幻覺時,迭代您的提示直到不再看到它為止。(請記住,多輪對話真的會對LLM的函數呼叫能力造成壓力,所以您的評估需要反映您的真實世界、多輪對話。)
- 當您期望LLM進行網絡搜索時,它會產生幻覺。內建的搜索基礎是LLM API的一個相對較新的功能。目前,LLM是否會選擇執行搜索仍然有點不可預測。如果它們不搜索,它們可能會用(較舊的)嵌入在其權重中的知識來回應,或者產生幻覺。與函數呼叫幻覺不同,這不是特別容易通過提示來修復。但很容易知道是否實際執行了搜索。因此,您可以在應用程序UI中顯示該信息或將其注入到語音對話中。如果您的應用依賴於網絡搜索,這樣做是個好主意。您是將問題推給用戶去理解和處理,但這比向用戶隱藏「搜索了」或「沒有搜索」的區別要好。從積極的方面來看,當搜索基礎有效時,它可以在很大程度上消除過時知識問題。
所有主要實驗室的API都有非常好的內容安全過濾器。
提示注入緩解也比一年前好得多,但隨著LLM獲得新功能,潛在提示注入攻擊的表面積也在擴大。例如,現在圖像中的文本提示注入已成為一個問題。
作為一個非常非常一般的指導原則:今天在語音AI使用場景中,您不太可能看到由正常用戶行為引起的意外提示注入。但是,完全通過用戶輸入,確實可以引導LLM行為以破壞系統指令。考慮到這一點,測試您的代理很重要。特別重要的是,對於訪問後端系統的任何函數,都要對LLM生成的輸入進行清理和交叉檢查。
5.4. 執行單一推理動作
對於AI工程師來說,學習如何利用LLM是一個持續的過程。這個過程的一部分是我們如何看待這些新工具的思維轉變。當我們第一次開始使用LLM時,大多數人都是通過語言模型有哪些獨特能力?這個視角來思考它們。但LLM是通用工具。它們在非常廣泛的信息處理任務中表現出色。
在語音代理環境中,我們總是設置了執行LLM推理的代碼路徑。我們不需要將LLM的使用僅限於核心對話循環。
例如:
- 每當您想使用正則表達式時,您可能可以改為編寫提示。
- 後處理LLM輸出通常很有用。例如,您可能希望以兩種格式生成輸出:用於在UI中顯示的文本和用於互動對話的語音。您可以提示對話LLM生成格式良好的markdown文本,然後再次提示LLM縮短並重新格式化文本以進行語音生成。[51]
- 遞迴是強大的。[52]您可以做一些事情,比如讓LLM生成一個列表,然後再次呼叫LLM對列表中的每個元素執行操作。
- 事實證明,您經常需要總結多輪對話。LLM是出色的、可引導的總結工具。更多內容請參見下面的腳本編寫和指令遵循部分。
[51] 關於後處理LLM輸出,另請參見上面的內容護欄部分。
[52] 我們是程式設計師,當然我們 … — 編者註
這些新興的程式碼模式中,許多看起來像是語言模型使用自己或另一個語言模型作為工具。
這是一個如此強大的想法,我們預計在2025年會看到很多人在這方面工作。代理框架可以將對此的支持構建到其庫級API中。模型可以被訓練以遞迴方式執行推理,這與訓練它們呼叫函數和執行代碼大致類似。
5.5. 邁向自我改進系統
當我們通過API訪問最先進的「模型」時,我們並不是在訪問單一成品。API背後的系統使用各種路由、多階段處理和分布式系統技術來快速、靈活、可靠地進行推理,並且規模非常大。這些系統總是在不斷調整。權重會更新。低級推理實現一直在變得更加高效。系統架構不斷發展。
大型實驗室不斷縮短用戶使用其API的方式與他們實現推理和其他功能的方式之間的反饋循環。
這些不斷加快的反饋循環是當今驚人的宏觀AI進步的重要組成部分。
從中獲得靈感,我們的代理級代碼中的微觀反饋循環可能是什麼樣子?我們能否建立特定的框架,在對話過程中改進代理性能?
- 監控代理在用戶尚未說完話之前打斷用戶的頻率,並動態調整VAD超時等參數。
- 監控用戶打斷代理的頻率,並動態調整LLM回應長度。
- 尋找表明用戶難以理解對話的模式 — 也許用戶不是母語使用者。調整對話風格或提供切換語言的選項。
您能想到其他想法嗎?
使用者: MNI最近表現如何?
代理: 邁阿密海豚隊昨天以21比3贏得比賽,目前在常規賽
還剩兩場比賽的情況下領先美聯東區。
使用者: 不,我指的是MNI股票。
代理: 啊,非常抱歉!您是在詢問MNI的股票表現,
這是McClatchy公司的股票代碼...
從這一刻起,模型將傾向於將音素或轉錄文本
解釋為"MNI"而非"邁阿密"。
一個LLM根據使用者反饋在多輪對話中調整行為的例子(上下文學習)
6. 腳本編寫和指令遵循
一年前,僅僅能夠構建能夠以自然人類延遲進行開放式對話的語音代理就已經令人興奮了。
現在我們正在部署語音AI代理來完成複雜的現實世界任務。對於當今的使用案例,我們需要指導LLM在會話期間專注於特定目標。通常,我們需要LLM按特定順序執行子任務。
例如,在醫療保健患者接診流程中,我們希望代理:
- 在做任何其他事情之前先驗證患者的身份。
- 確保詢問患者目前正在服用的藥物。
- 如果患者說他們正在服用藥物X,問一個特定的後續問題。
- 等等...
我們將制定逐步工作流程稱為腳本編寫。過去一年語音AI開發的一個教訓是,僅靠提示工程很難實現腳本的可靠性。
單一提示中能夠包含的細節是有限的。相關地,隨著多輪對話中上下文的增長,LLM需要跟踪越來越多的信息,指令遵循的準確性也會下降。
許多語音AI開發者正在轉向使用狀態機方法來構建複雜的工作流程。我們可以定義一系列狀態,而不是編寫一個長而詳細的系統指令來引導LLM。每個狀態包括:
- 一個系統指令和工具列表。
- 一個對話上下文。
- 從當前狀態到另一個狀態的一個或多個出口。
每個狀態轉換都是一個機會,可以:
- 更新系統指令和工具列表。
- 總結或修改上下文。[53]
[53] 通常,您會進行LLM推理調用來執行上下文總結。 :-)
狀態機方法之所以有效,是因為更短、更專注的系統指令、工具列表和上下文顯著提高了LLM的指令遵循能力。
挑戰在於找到正確的平衡點:一方面利用LLM進行開放式、自然對話的能力,另一方面確保LLM可靠地執行工作中重要的部分。
Pipecat Flows是一個建立在Pipecat之上的庫,幫助開發者創建工作流程狀態機。
狀態圖以JSON表示,可以加載到Pipecat進程中。有一個圖形編輯器用於創建這些JSON狀態圖。
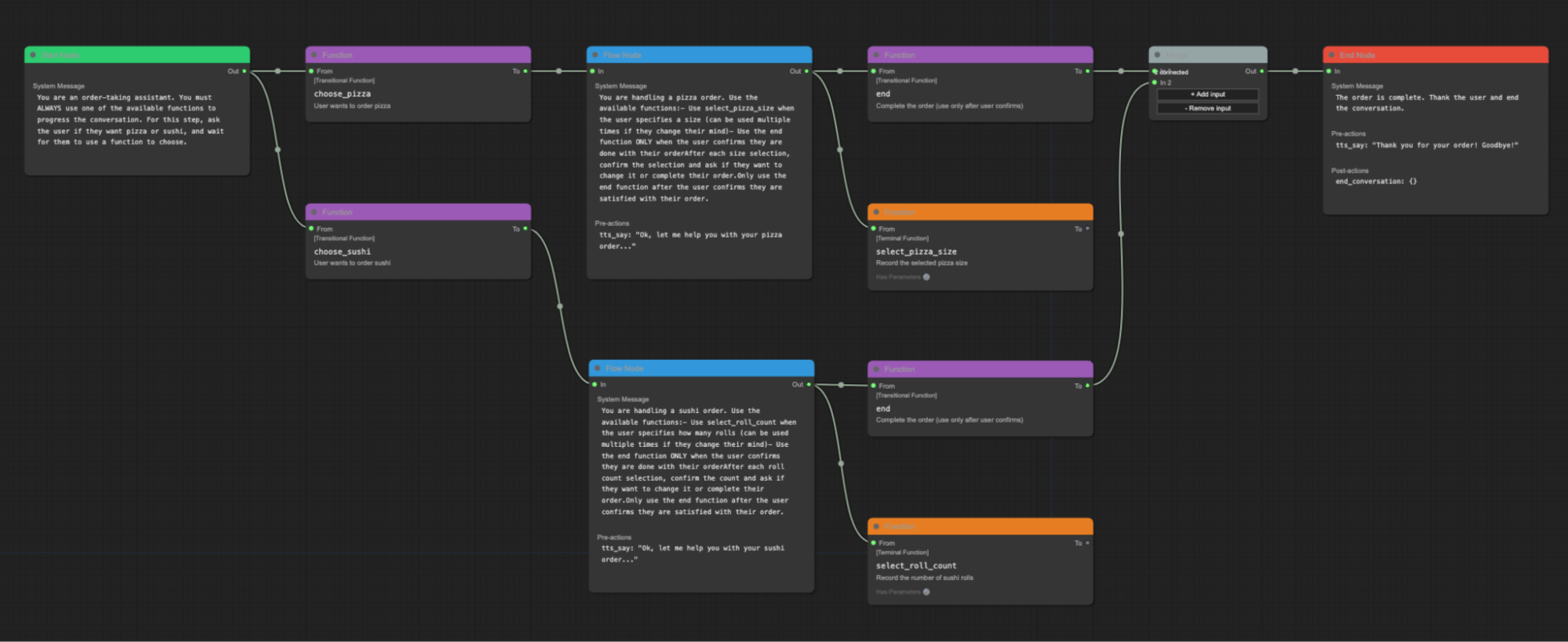
Pipecat Flows圖形編輯器
Pipecat Flows和狀態機目前正受到許多開發者的採用。但還有其他有趣的方式來思考如何為複雜工作流程構建抽象。
AI研究和開發的一個活躍領域是多代理系統。您可以將工作流程視為多代理系統,而不是一系列要遍歷的狀態。
Pipecat的核心架構組件之一是並行管道。並行管道允許您分割通過處理圖的數據並對其進行兩次(或更多次)操作。您可以阻塞和過濾數據。您可以定義多個並行管道。您可以將工作流程視為一組受控制、協調的並行管道。
語音AI工具的快速發展令人興奮,並突顯出我們在找出構建這些新型程序的最佳方式方面還處於早期階段。
7. 語音AI評估
一種非常重要的工具類型是評估(eval),即評估的簡稱。
評估是機器學習術語,指評估系統能力並判斷其質量的工具或過程。
7.1. 語音AI評估與軟體單元測試不同
如果您來自傳統軟體工程背景,您習慣於將測試視為(大多數情況下)確定性的練習。
語音AI需要與傳統軟體工程不同的測試。語音AI輸出是非確定性的。測試語音AI的輸入是複雜的、分支的、多輪對話。
您需要運行概率性評估,而不是測試特定輸入產生特定輸出(f(x) = y)—進行大量測試運行,以查看某種類型的事件發生的頻率。[54]對於某些測試,在10次中有8次正確處理某類案例是可接受的,而對於其他測試,準確率需要達到10次中的9.99次。
[54] 使用者請求被滿足、代理打斷使用者、代理偏離主題等
您將有許多輸入,而不僅僅是一個:所有的使用者回應。這使得在不嘗試模擬使用者行為的情況下測試語音AI應用程序變得非常困難。
最後,語音AI測試具有非二元結果,很少像傳統單元測試那樣產生明確的✅或❌。相反,您需要審查結果並決定權衡。
7.2. 失敗模式
語音AI應用程序具有特定的形式和失敗模式,這些影響我們如何設計和運行評估。延遲是關鍵(因此在文本模式系統中可接受的延遲對於語音系統來說是失敗)。它們是多模型的(性能不佳可能是由TTS不穩定而不是LLM行為引起的)。
當今經常出現挑戰的一些領域是:
- 首次發言時間和代理回應時間的延遲
- 轉錄錯誤
- 理解和口頭表達地址、電子郵件、姓名、電話號碼
- 中斷
7.3. 制定評估策略
一個基本的評估過程可以簡單如一個包含提示和測試案例的電子表格。
一種典型的方法是在測試新模型或更改系統的主要部分時運行每個提示,使用LLM來判斷回應是否在某些預期參數的定義範圍內。
擁有基本評估比完全沒有評估要好得多。但隨著您開始大規模運營,投資於評估—擁有真正好的評估—變得至關重要。
專為語音AI用例提供複雜工具的評估平台才剛開始出現。三個較早投資於音訊評估特定工作流程和工具的平台是Coval、FreePlay和Weights & Biases Weave。這三個平台都有良好的Pipecat整合。
Coval評估平台UI的截圖
這些平台可以幫助:
- 提示詞迭代。
- 音訊、工作流程、函數呼叫和對話語義評估的現成指標。
- 針對問題區域進行優化(例如,讓您的代理更好地處理中斷)。
- 回歸測試(確保在修復一個問題區域時不會在其他先前已解決的問題區域引入回歸)。
- 追蹤隨時間變化的性能,包括開發人員所做的更改和跨用戶群體的變化。
8. 與電話基礎設施整合
當今增長最快的語音AI用例大多涉及電話通話。AI語音代理現在正在大規模接聽和撥打電話。
部分應用發生在傳統客服中心。客服中心主要將語音AI視為可以提高「轉移率」的技術 — 即可以由自動化而非人工客服處理的通話百分比。這使得採用語音AI的投資回報率變得明確。如果LLM的每分鐘成本低於人工客服的每分鐘成本,購買決策就很容易做出。[55]
[55] 當然,這是假設AI代理的表現良好。而對於當今各種客戶支援用例,它確實表現良好。
不過,除了簡單的投資回報率計算外,還有一些有趣的事情正在加速採用。
語音AI代理的可擴展性遠超人工團隊。一旦您部署了語音AI,高峰期的等待時間就會減少。(客戶滿意度評分因此直接提高。)
而且LLM有時能比人工客服做得更好,因為我們給它們提供了更好的工具。在許多客戶支援情況下,人工客服必須處理多個遺留後端系統。及時找到資訊可能是一項挑戰。當我們在相同情況下部署語音AI時,我們必須建立這些遺留系統的API級別存取。新的LLM加API層正在促進向語音AI的技術轉型。
很明顯,生成式AI將在未來幾年徹底重塑客服中心格局。
在客服中心之外,語音AI正在改變小型企業如何接聽電話,以及如何使用電話進行資訊發現和協調。我們每天都與正在為您聽說過的各種商業領域構建專業AI電話解決方案的新創公司交流。
這個領域的人常開玩笑說,很快人類將不再撥打或接聽電話。所有電話都將是AI對AI的通話。從我們看到的趨勢來判斷,這確實有一定道理!
如果您對語音AI的電話技術感興趣,有幾個縮寫詞和常見概念您應該熟悉。
- PSTN是公共交換電話網路(public, switched, telephone network)。如果您需要與有電話號碼的真實電話互動,您需要使用PSTN平台。Twilio是幾乎每個開發人員都聽說過的PSTN平台。
- SIP是用於IP電話的特定協議,但在一般意義上,SIP用於指系統之間的電話互連。例如,如果您正在與客服中心技術堆疊對接,您需要使用SIP。您可以使用SIP提供商,或託管自己的SIP伺服器。
- DTMF音調是用於導航電話選單的按鍵聲音。語音代理需要能夠發送DTMF音調以與現實世界的電話系統互動。LLM在處理電話樹方面相當不錯。您只需要做一些提示詞工程並定義發送DTMF音調的函數。
- 語音代理通常需要執行通話轉接。在簡單轉接中,語音AI通過呼叫觸發通話轉接的函數來退出會話。[56]熱轉接(warm transfer)是從一個代理到另一個代理的交接,其中代理在將來電者轉接給第二個代理之前相互交談。語音AI代理可以像人類一樣進行熱轉接。語音代理最初與人類來電者交談,然後將人類來電者置於保留狀態,與被引入通話的新人類代理進行對話,然後將人類來電者連接到人類代理。
[56] 實際的轉接操作可能是對您的電話平台的API呼叫,或SIP REFER動作。
9. RAG和記憶
語音AI代理經常需要從外部系統獲取資訊。例如,您可能需要:
- 將有關用戶的資訊整合到LLM系統指令中。
- 檢索先前的對話歷史。
- 在知識庫中查詢資訊。
- 執行網路搜尋。
- 進行即時庫存或訂單狀態檢查。
所有這些都屬於RAG(檢索增強生成,Retrieval Augmented Generation)的範疇。RAG是結合資訊檢索和LLM提示的通用AI工程術語。
語音代理的「最簡單的RAG」是在對話開始前查詢用戶資訊,然後將該資訊合併到LLM系統指令中。
user_info = fetch_user_info(user_id)
system_prompt_base = "You are a voice AI assistant..."
system_prompt = (
system_prompt_base
+ f"""
The name of the patient is {user_info["name"]}.
The patient is {user_info["age"]} years old.
The patient has the following medical history: {user_info["summarized_history"]}.
"""
)
簡單的RAG – 在會話開始時執行查詢
RAG是一個深入的主題,也是一個快速變化的領域。[57]技術範圍從上述相對簡單的方法(僅使用基本查詢和字串插值),到使用嵌入和向量資料庫組織大量半結構化資料的系統。
[57] 嗯,這聽起來像是當今生成式AI的每個其他領域。
通常,80/20法則可以讓您走很長一段路。如果您已有知識庫,請使用您已有的API。編寫簡單的評估,以便測試幾種不同的格式,將查詢結果注入到對話上下文中。部署到生產環境,然後監控這在真實用戶中的效果如何。
async def query_order_system(function_name, tool_call_id, args, llm, context, result_callback):
"First push a speech frame. This is handy when the LLM response might take a while."
await llm.push_frame(TTSSpeakFrame("Please hold on while I look that order up for you."))
query_result = order_system.get(args["query"])
await result_callback({
"info": json.dumps({
"lookup_success": True,
"order_status": query_result["order_status"],
"delivery_date": query_result["delivery_date"],
})
})
llm.register_function("query_order_system", query_order_system)
會話期間的RAG。為LLM定義一個在需要查詢資訊時可以呼叫的函數。在此範例中,我們還發出預設的語音短語,讓用戶知道系統需要幾秒鐘來回應。
一如既往,延遲對語音AI來說是比非語音AI系統更大的挑戰。當LLM發出函數呼叫請求時,額外的推理呼叫會增加延遲。在外部系統中查詢資訊也可能很慢。在執行RAG查詢之前觸發簡單的語音輸出通常很有用,讓用戶知道系統正在處理中。
更廣泛地說,跨會話的記憶是一個有用的功能。想像一個需要記住您所談論的一切的語音AI個人助理。兩種通用方法是:
- 將每次對話保存到持久存儲中。測試幾種將對話加載到上下文中的方法。例如,對於個人助理用例效果良好的策略:在代理啟動時始終完整加載最近的對話,加載最近N次對話的摘要,並定義一個LLM可以用來根據需要動態加載較舊對話的查詢函數。
- 將對話歷史中的每條訊息與訊息圖的元數據一起單獨保存在資料庫中。為每條訊息建立索引(可能使用語義嵌入)。這允許您動態構建分支對話歷史。如果您的應用大量使用圖像輸入(LLM視覺),您可能想要這樣做。圖像在上下文空間中佔用很多空間![58]這種方法還允許您構建分支UI,這是AI應用設計師剛開始探索的方向。
[58] 參見多模態。
10. 託管和擴展
語音AI應用程式通常有一些傳統的應用程式組件 — 網頁應用前端、API端點和其他後端元素。但代理程序本身與傳統應用程式組件有很大不同,因此部署和擴展語音AI帶來了獨特的挑戰。
10.1 架構
- 語音AI代理對話循環通常是一個長時間運行的程序(不是在單個回應完成生成後就退出的請求/回應函數)。
- 語音代理實時串流音訊。任何阻礙串流的因素都可能造成音訊故障。(共享虛擬機器上的CPU峰值,即使只有10毫秒的程序流程阻塞音訊執行緒等。)
- 語音代理通常需要WebSocket或WebRTC連接。雲服務網路閘道和路由產品對WebSockets的支援遠不如對HTTP的支援。它們通常根本不支援UDP。(WebRTC需要UDP。)
基於所有這些原因,通常無法使用AWS Lambda或Google Cloud Run等無伺服器框架來運行語音AI。
目前部署語音AI代理的最佳實踐是:
- 一旦您度過了原型階段,請投入工程時間創建輕量級工具來構建Docker(或類似)容器以部署您的代理。
- 將您的容器推送到您選擇的計算平台。對於簡單的部署,您可以只保持固定數量的虛擬機器運行。但在某個時候,您會希望連接到平台的工具,以便自動擴展、優雅地部署新版本、實現良好的服務發現和故障轉移,以及構建其他大規模的DevOps需求。
- Kubernetes現在是管理容器、部署和擴展的標準。Kubernetes有陡峭的學習曲線,但所有主要雲平台都支援它。Kubernetes擁有非常龐大的生態系統。
- 對於部署軟體更新,您需要設置長時間的排空時間,允許現有連接保持活動狀態直到會話結束。在Kubernetes中做到這一點並不特別困難,但細節取決於您的k8s引擎和版本。
- 冷啟動對語音AI代理來說是個問題,因為快速連接時間很重要。保持一個閒置的代理池是避免長時間冷啟動的最簡單方法。如果您的工作負載不需要在本地運行大型模型,通常可以在不太費力的情況下設計快速容器冷啟動。[59]
虛擬機器規格和容器打包在首次部署到生產環境時常常讓人困惑。您的代理需要的規格將根據您使用的庫和在代理程序中執行的CPU密集型工作量而有所不同。一個好的經驗法則是從每個虛擬機器CPU運行一個代理開始,RAM為您在開發機器上看到代理程序消耗的最大RAM量的兩倍。[60]
[59] 如果您在本地運行大型模型,有關冷啟動的建議遠超出本指南的範圍。如果您還不是GPU和容器優化專家,您可能想找一位專家,而不是自己攀爬那個學習曲線(至少在您的運營規模足夠大以攤銷開發所需工具的成本之前)。
[60] 確保您的容器運行時在閒置的CPU上啟動新的代理程序。這並不總是k8s的默認設置。
10.2 計算每分鐘成本
語音AI的成本因使用的模型、API和託管基礎設施而有很大差異。成本也取決於使用案例。例如,如上方成本比較所討論的,對於較長的會話,每分鐘成本通常較高。而且電話通訊比WebRTC傳輸更昂貴。
成本範圍從每分鐘0.20美元或更高(如果您使用的是像OpenAI Realtime API這樣的語音到語音API),到每分鐘0.10美元(對於包含所有功能的託管代理平台),再到每分鐘0.02美元(對於在大規模運行的高度成本優化部署)。
我們有時看到人們犯的一個錯誤是在計算語音和LLM API成本之前就優化代理託管本身。一般來說,代理程序本身的雲端運行成本不到總每分鐘成本的百分之一。幾乎不值得花費工程努力來優化每個虛擬CPU的代理並發性。
這裡有一個試算表,您可以複製並用作計算每分鐘成本的起點。
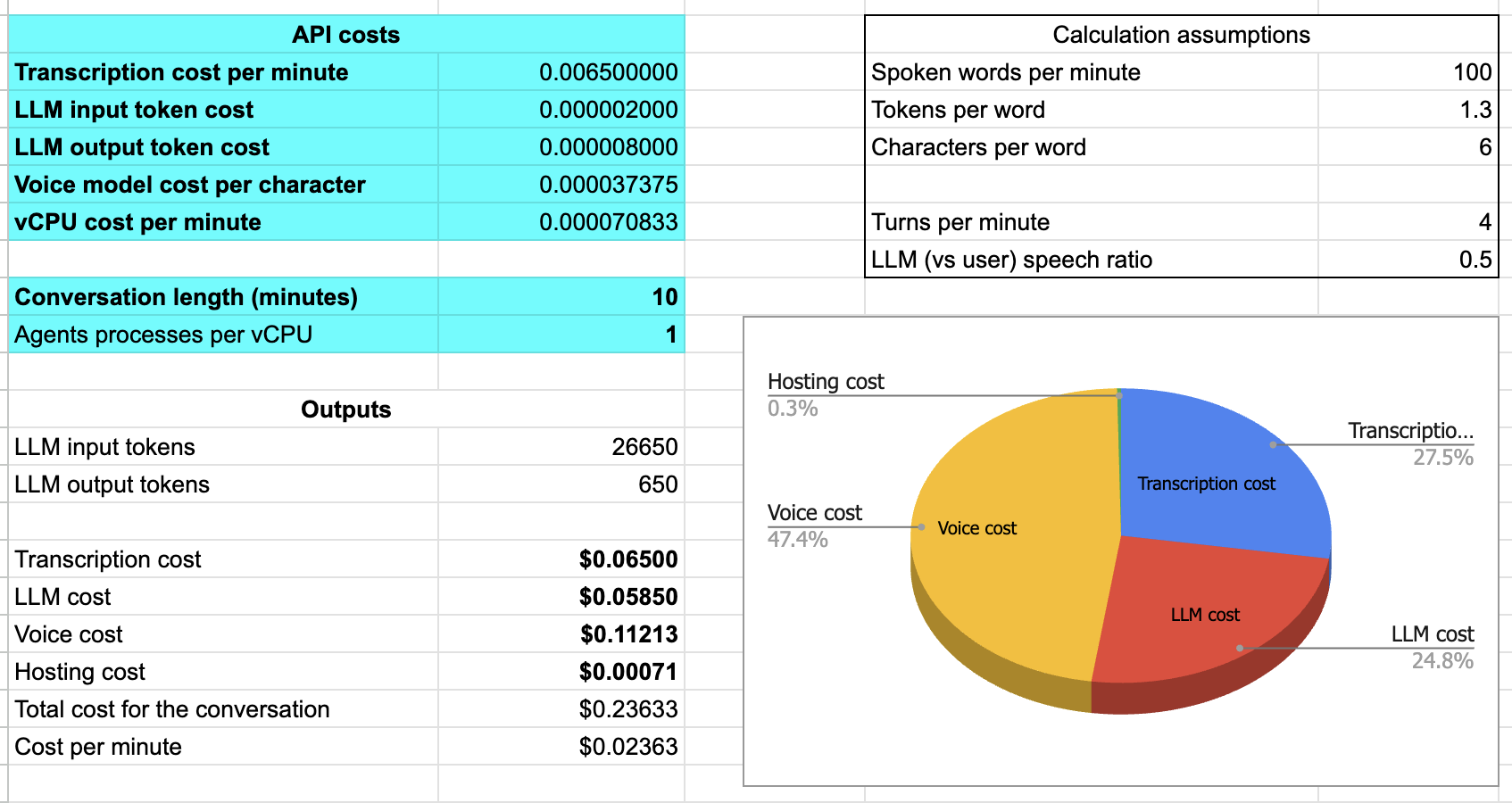
計算語音AI代理每分鐘成本的試算表
截圖中的數字是針對使用Deepgram、GPT-4o和Cartesia的自託管代理。對於十分鐘的會話,每分鐘成本約為兩分半美分。轉錄和LLM推理各佔成本的四分之一。語音生成約佔成本的一半。託管成本不到總成本的百分之一。
當然,這並不是自託管實際成本的真實圖景。如果您正在構建和維護所有自己的託管基礎設施,除了代理本身外,您還需要設置、擴展和維護許多系統和功能。
- 服務發現
- 負載平衡
- 日誌記錄
- 監控
- 頻寬
- 多區域部署
- 安全性
- 合規和監管功能(例如數據駐留)
- 分析
- 客戶支援
11. 2025年的展望
談到AI工程的成長,語音AI在2024年有了巨大的發展,我們預計這種趨勢將在2025年持續。
這種不斷擴大的興趣和採用將在一些重要的核心領域創造持續進步:- 所有模型開發者和服務提供商都將進一步優化延遲。長期以來,大多數實施服務的人員和幾乎所有已發布的基準測試都專注於吞吐量而非延遲。對於語音AI,我們更關心首個token的生成時間,而不是每秒token數量。
- 朝向在模型和API中完全整合所有非文本模態的進展。
- 測試和評估工具中更多的音訊特定功能。
- 支援實時多模態用例需求的上下文快取API。
- 來自多個提供商的新語音代理平台。
- 來自多個提供商的語音到語音模型API。
- 能夠納入上下文以提高轉錄準確性和語音生成質量的上下文語音模型。
如果您對2025年四位語音AI領域專家的熱門觀點感興趣,請跳到一月舊金山語音AI聚會錄影的54:05處。Karan Goel、Niamh Gavin、Shrestha Basu-Mallick和Swyx都提供了他們對未來一年的預測:通用記憶、AI在好萊塢的應用、從模型模仿到模型理解的轉變,以及對機器人技術的一種反向觀點。
這將是一個有趣的一年。
貢獻者
主要作者
Kwindla Hultman Kramer
感謝Brooke Hopkins協助評估部分,Zach Koch提供關於Llama性能和Ultravox的見解,以及Brendan Iribe提供關於上下文語音模型重要性轉變的註解。
貢獻作者[61]
aconchillo, markbackman, filipi87, Moishe, kwindla, kompfner, Vaibhav159, chadbailey59, jptaylor, vipyne, Allenmylath, TomTom101, adriancowham, imsakg, DominicStewart, marcus-daily, LewisWolfgang, mattieruth, golbin, adithyaxx, jamsea, vr000m, joachimchauvet, sahilsuman933, adnansiddiquei, sharvil, deshraj, balalofernandez, MaCaki, TheCodingLand, milo157, RJSkorski, nicougou, AngeloGiacco, kylegani, kunal-cai, lazeratops, EyrisCrafts, roey-priel, aashsach, jcbjoe, Dev-Khant, wg-daniel, cbrianhill, ankykong, nulyang, flixoflax, DANIIL0579, Antonyesk601, rahultayal22, lucasrothman, CarlKho-Minerva, 0xPatryk, pvilchez, pedro-a-n-moreira, RonakAgarwalVani, xtreme-sameer-vohra, shaiyon, soof-golan, yashn35, zboyles, balaji-atoa, eddieoz, mercuryyy, rahulunair, porcelaincode, weedge, wtlow003, zzz-heygen, adidoit, ArmanJR, Bnowako, chhao01, Regaddi, cyrilS-dev, DamienDeepgram, danthegoodman1, dleybz, ecdeng, gregschwartz, KevGTL, louisjoecodes, M1ngXU, mattmatters, MoofSoup, natestraub
設計
Sascha Mombartz
Akhil K G
[61] GitHub使用者名稱,github.com/pipecat-ai/pipecat/graphs/contributors